Design and Analysis of Algorithms
Introduction
Every complex problem has a solution that is clear, simple, and wrong. — H. L. Mencken
Welcome to Foundations of Computer Science! This text covers foundational aspects of Computer Science that will help you reason about any computing task. In particular, we are concerned with the following with respect to problem solving:
What are common, effective approaches to designing an algorithm?
Given an algorithm, how do we reason about whether it is correct and how efficient it is?
Are there limits to what problems we can solve with computers, and how do we identify whether a particular problem is solvable?
What problems are efficiently solvable, and how do we determine whether a particular problem is?
For problems that seem not to be solvable efficiently, can we efficiently find approximate solutions, and what are common techniques for doing so?
Can randomness help us in solving problems?
How can we exploit problems that are not efficiently solvable to build secure cryptography algorithms?
In order to answer these questions, we must define formal mathematical models and apply a proof-based methodology. Thus, this text will feel much like a math text, but we apply the approach directly to widely applicable problems in Computer Science.
As an example, how can we demonstrate that there is no general algorithm for determining whether or not two programs have the same functionality? A simple but incorrect approach would be to analyze all possible algorithms, and show that none can work. However, there are infinitely many possible algorithms, so we have no hope of this approach working. Instead, we need to construct a model that captures the notion of what is computable by any algorithm, and use that to demonstrate that no such algorithm exists.
Text Objectives
The main purpose of this text is to give you the tools to approach computational problems you’ve never seen before. Rather than being given a particular algorithm or data structure to implement, approaching a new problem requires reasoning about whether the problem is solvable, how to relate it to problems that you’ve seen before, what algorithmic techniques are applicable, whether the algorithm you come up with is correct, and how efficient the resulting algorithm is. These are all steps that must be taken prior to actually writing code to implement a solution, and these steps are independent of your choice of programming language or framework.
Thus, in a sense, the fact that you will not have to write code (though you are free to do so if you like) is a feature, not a bug. We focus on the prerequisite algorithmic reasoning required before writing any code, and this reasoning is independent of the implementation details. If you were to implement all the algorithms you design in this course, the workload would be far greater, and it would only replicate the coding practice you get in your programming courses. Instead, we focus on the aspects of problem solving that you have not yet had much experience in. The training we give you in this text will make you a better programmer, as algorithmic design and analysis is crucial to effective programming. This text also provides a solid framework for further exploration of theoretical Computer Science, should you wish to pursue that path. However, you will find the material here useful regardless of which subfields of Computer Science you decide to study.
As an example, suppose your boss tells you that you need to make a business trip to visit several cities, and you must minimize the cost of visiting all those cities. This is an example of the classic traveling salesperson problem, and you may have heard that it is an intractable problem. What exactly does that mean? Does it mean that it cannot be solved at all? What if we change the problem so that you don’t have to minimize the cost, but instead must fit the cost within a given budget (say $2000)? Does this make the problem any easier? What if we don’t require that the total cost be minimized, but that it merely needs to be within a factor of two of the optimal cost?
Before we can reason about the total cost of a trip, we need to know how much it costs to travel between two consecutive destinations in the trip. Suppose we are traveling by air. There may be no direct flight between those two cities, or it might be very expensive. To help us keep our budget down, we need to figure out what the cheapest itinerary between those two cities is, considering intermediate layover stops. And since we don’t know a priori in what order we will visit all the cities, we need to know the cheapest itineraries between all pairs of cities. This is an instance of the all-pairs shortest path problem. Is this an “efficiently solvable” problem, and if so, what algorithmic techniques can we use to find a solution?
We will consider both of the problems above in this text. We will learn what it means for a problem to be solvable or not (and how to prove this), what it means for a problem to be tractable or not (and how to prove that it is, or give strong evidence that it is not), and techniques for designing and analyzing algorithms for tractable problems.
Tools for Abstraction
Abstraction is a core principle in Computer Science, allowing us to reason about and use complex systems without needing to pay attention to implementation details. As mentioned earlier, the focus of this text is on reasoning about problems and algorithms independently of specific implementations. To do so, we need appropriate abstract models that are applicable to any programming language or system architecture.
Our abstract model for expressing algorithms is pseudocode, which describes the steps in the algorithm at a high level without implementation details. As an example, the following is a pseudocode description of the Floyd-Warshall algorithm, which we will discuss later:
This description is independent of how the graph \(G\) is represented, or the two-dimensional matrices \(d_i\), or the specific syntax of the loops. Yet it should be clear to the intended reader what each step of the algorithm does. Expressing this algorithm in a real-world programming language like C++ would only add unnecessary syntactic and implementation details that are an artifact of the chosen language and data structures, and not intrinsic to the algorithm itself. Instead, pseudocode gives us a simple means of expressing an algorithm that facilitates understanding and reasoning about its core elements.
We also need abstractions for reasoning about the efficiency of algorithms. The actual real-world running time and space/memory usage of a program depend on many factors, including choice of language and data structures, available compiler optimizations, and characteristics of the underlying hardware. Again, these are not intrinsic to an algorithm itself. Instead, we focus not on concrete real-world efficiency, but on how the algorithm’s running time (and sometime memory usage) scales with respect to the input size. Specifically, we focus on time complexity in terms of:
the number of basic operations performed as a function of input size,
asymptotically, i.e., as the input size grows,
ignoring leading constants,
over worst-case inputs.
We measure space complexity in a similar manner, but with respect to the number of memory cells used, rather than the number of basic operations performed. These measures of time and space complexity allow us to evaluate algorithms in the abstract, rather than with respect to a particular implementation. This is not to say that absolute performance is irrelevant. Rather, the asymptotic complexity gives us a “higher-level” view of an algorithm. An algorithm with poor asymptotic time complexity will be inefficient when run on large inputs, regardless of how good the implementation is.
Later in the text, we will also reason about the intrinsic solvability of a problem. We will see how to express problems in the abstract (e.g. as languages and decision problems), and we will examine a simple model of computation (Turing machines) that captures the essence of computation.
The First Algorithm: Euclid’s GCD
One of the oldest known algorithms is Euclid’s algorithm for computing the greatest common divisor (GCD) of two integers.
Let \(x \in \Z\) be an integer. We say that an integer \(d\) divides \(x\) (and is a divisor of \(x\)) if there exists an integer \(k \in \Z\) such that \(d \cdot k = x\). (When \(d \neq 0\), this is equivalent to \(x/d\) being an integer.)
Whether \(d\) divides \(x\) is not affected by their signs (positive, negative, or zero), so from now on we restrict our attention to nonnegative integers and divisors.
Note: \(d=1\) divides any integer \(x\), by taking \(k=x\) (i.e., \(1 \cdot x = x\)), and \(d=x\) is the largest divisor of \(x\) when \(x > 0\). Take care with the special cases involving zero: any integer \(d\) divides \(x=0\), because \(d \cdot 0 = 0\). But \(d=0\) does not divide anything except \(x=0\), because \(d \cdot k = 0 \cdot k = 0\) for every \(k\).
Let \(x,y \in \Z\) be nonnegative integers. A common divisor of \(x,y\) is an integer that divides both of them, and their greatest common divisor, denoted \(\gcd(x,y)\), is the largest such integer.
For example, \(\gcd(21,9) = 3\) and \(\gcd(121, 5) = 1\). Also, \(\gcd(7,7) = \gcd(7,0) = 7\). (Make sure you understand why!) If \(\gcd(x,y) = 1\), we say that \(x\) and \(y\) are coprime. So, 121 and 5 are coprime, but 21 and 9 are not coprime (nor are 7 and 7, nor are 7 and 0).
Take note: as long as \(x,y\) are not both zero, \(\gcd(x,y)\) is well defined, because there is at least one common divisor \(d=1\), and no common divisor can be greater than \(\max(x,y)\). However, \(\gcd(0,0)\) is not well defined, because every integer divides zero, and there is no largest integer. In this case, it is convenient to define \(\gcd(0,0)=0\), so that \(\gcd(x,0)=x\) for all \(x\).
So far we have just defined the GCD mathematically. Now we consider the computational question: given two integers, can we compute their GCD, and how efficiently can we do so? As we will see later, this problem turns out to be very important in cryptography and other fields.
Here is a naïve, “brute-force” algorithm for computing the GCD of given integers \(x \geq y\) (we adopt this requirement for convenience, since we can swap the values without changing the answer): try every integer from \(y\) down to 1, check whether it divides both \(x\) and \(y\), and return the first (and hence largest) such number that does. The algorithm is clearly correct, because the GCD of \(x\) and \(y\) cannot exceed \(y\), and the algorithm returns the first (and hence largest) value that actually divides both arguments.
Here, the \(\bmod\) operation computes the remainder of the first operand divided by the second. For example, \(9 \bmod 6 = 3\) since \(9 = 6 \cdot 1 + 3\), and \(9 \bmod 3 = 0\) since \(9 = 3 \cdot 3 + 0\). So, the result of \(x \bmod d\) is an integer in the range \([0, d-1]\), and in particular \(x \bmod 1 = 0\). The result is not defined when \(d\) is 0.
How efficient is the above algorithm? In the worst case, it performs two \(\bmod\) operations for every integer in the range \([1, y]\). Using asymptotic notation, the worst-case number of \(\bmod\) operations is therefore \(\Theta(y)\). (Recall that this \(\Theta(y)\) notation means: between \(c y\) and \(c' y\) for some positive constants \(c,c'\), for all “large enough” \(y\).)
Can we do better?
Here is a key observation: if \(d\) divides both \(x\) and \(y\), then it also divides \(x - my\) for any integer \(m \in \Z\). Here is the proof: since \(x = d \cdot a\) and \(y = d \cdot b\) for some integers \(a,b \in \Z\), then \(x - my = da - mdb = d \cdot (a - mb)\), so \(d\) divides \(x - my\) as well. By the same kind of reasoning, the converse holds too: if some \(d'\) divides both \(x - my\) and \(y\), it also divides \(x\). Thus, the common divisors of \(x\) and \(y\) are exactly the common divisors of \(x - my\) and \(y\), and hence the greatest common divisors of these two pairs are equal. We have just proved the following:
For all \(x,y,m \in \Z\), we have \(\gcd(x, y) = \gcd(x - my, y)\).
Since any \(m \in \Z\) will do, let’s choose \(m\) to minimize \(x - my\), without making it negative. As long as \(y \neq 0\), we can do so by taking \(m = \floor{x/y}\), the integer quotient of \(x\) and \(y\). Then \(r = x - my = x - \floor{x/y}y\) is simply the remainder of \(x\) when divided by \(y\), i.e., \(r = x \bmod y\).
The above results in the following corollary (where the second equality holds because the GCD is symmetric):
For all \(x, y \in \Z\) with \(y \neq 0\), we have \(\gcd(x, y) = \gcd(x \bmod y, y) = \gcd(y, x \bmod y)\).
(The rightmost expression maintains our convention that the first argument of \(\gcd\) should be greater than or equal to the second.)
We have just derived the key recurrence relation for \(\gcd\), which we will use as the heart of an algorithm. However, we also need base cases. As mentioned previously, \(x \bmod y\) is defined only when \(y \neq 0\), so we need a base case for \(y = 0\). As we have already seen, \(\gcd(x,0) = x\) (even when \(x=0\)). (We can also observe that \(\gcd(x, 1) = 1\) for all \(x\). This latter base case is not technically necessary; some descriptions of Euclid’s algorithm include it, while others do not.)
This leads us to the Euclidean algorithm:
Here are some example runs of this algorithm:
How efficient is this algorithm? Clearly, it does one \(\bmod\) operation per iteration—or more accurately, recursive call—but it is no longer obvious how many iterations it performs. For instance, the computation of Euclid\((30, 19)\) does six iterations, while Euclid\((376281, 376280)\) does only two. There doesn’t seem to be an obvious relationship between the form of the input and the number of iterations.
This is an extremely simple algorithm, consisting of just a few lines of code. But that does not make it simple to reason about. We need new techniques to analyze code like this and determine its time complexity.
The Potential Method
Let’s set aside Euclid’s algorithm for the moment and examine a game
instead. Consider a “flipping game” that has an \(11\times 11\) board
covered with two-sided chips, say  on the front side and
on the front side and
 on the back. Initially, the entirety of the board is covered
with every chip face down.
on the back. Initially, the entirety of the board is covered
with every chip face down.

The game pits a row player against a column player, and both take turns flipping an entire row or column, respectively. A row or column may be flipped only if it contains more face-down (OSU) than face-up (UM) chips. The game ends when a player can make no legal moves, and that player loses the game. For example, if the game reaches the following state and it is the column player’s move, the column player has no possible moves and therefore loses.

Let’s set aside strategy and ask a simpler question: must the game end in a finite number of moves, or is there a way to play the game in a way that continues indefinitely?
An \(11\times 11\) board is rather large to reason about, so a good strategy is to simplify the problem by considering a \(3\times 3\) board instead. Let’s consider the following game state.

Suppose that it is the row player’s turn, and the player chooses to flip the bottom row.

Notice that in general, a move may flip some chips from UM to OSU, and others vice versa. This move in particular flipped the first chip in the row from UM to OSU, and the latter two chips from OSU to UM. The number of chips flipped in each direction depends on the state of a row or column, and it is not generally the case that every move flips three OSU chips to UM in the \(3\times 3\) board.
Continuing the game, the column player only has a single move available.

Again, one UM chip is flipped to OSU, and two OSU chips are flipped to UM.
It is again the row player’s turn, but now no row flips are possible. The game ends, with the victory going to the column player.
We observe that each move flipped both UM and OSU chips, but each move flipped more OSU chips to UM than vice versa. Is this always the case? Indeed it is, by rule: a move is legal only if the flipped row or column has more OSU than UM chips. The move flips each OSU chip to a UM one, and each UM chip to an OSU chip. Since there are more OSU than UM chips, more OSU-to-UM flips happen than vice versa. More formally and generally, for an \(n\times n\) board, an individual row or column has \(k\) OSU chips and \(n-k\) UM chips, for some value of \(k\). A move is legal when \(k > n-k\). After the flip, the row or column will have \(k\) UM chips and \(n-k\) OSU chips. The net change in the number of UM chips is \(k - (n-k)\), which is positive because \(k > n-k\). Thus, each move strictly increases the number of UM chips, and strictly decreases the number of OSU chips.
In the \(3\times 3\) case, we start with nine OSU chips. No board configuration can have fewer than zero OSU chips. Then because each move decreases the number of OSU chips, no more than nine moves are possible before the game must end. By the same reasoning, no more than 121 moves are possible in the original \(11\times 11\) game.
Strictly speaking, it will always take fewer than 121 moves to reach a configuration where a player has no moves available, because the first move decreases the number of OSU chips by eleven. But we don’t need an exact number to answer our original question. We have proved an upper bound of 121 on the number of moves, so we have established that any valid game must indeed end after a finite number of moves.
The core of the above reasoning is that we defined a special measure of the board’s state, namely, the number of OSU chips. We observe that in each step, this measure must decrease (by at least one). The measure of the initial state is finite, and there is a lower bound the measure cannot go below, so eventually that lower bound must be reached.
This pattern of reasoning is called the potential method. Formally, given some set \(A\) of “states” (e.g., game states, algorithm states, etc.), let \(s \colon A \to \R\) be a function that maps states to numbers. The function \(s\) is a potential function if:
it strictly decreases with every state transition (e.g., turn in a game, step of an algorithm, etc.) [1]
it is lower-bounded by some fixed value: there is some \(\ell \in \R\) for which \(s(a) \geq \ell\) for all \(a \in A\).
By defining a valid potential function and establishing both its lower bound and how quickly it decreases, we can upper bound the number of steps a complex algorithm may take.
A Potential Function for Euclid’s Algorithm
Let’s return to Euclid’s algorithm and try to come up with a potential function we can use to reason about its efficiency. Specifically, we want to determine an upper bound on the number of iterations the algorithm takes for a given input \(x\) and \(y\).
First observe that \(x\) and \(y\) do not increase from one step to the next. For instance, Euclid\((30,19)\) calls Euclid\((19,11)\), so \(x\) decreases from 30 to 19 and \(y\) decreases from 19 to 11. However, the amount each argument individually decreases can vary. In Euclid\((376281,376280)\), \(x\) decreases by only one in the next iteration, while \(y\) decreases by 376279. In Euclid\((7,7)\), \(x\) does not decrease at all in the next iteration, but \(y\) decreases by 7.
Since the algorithm has two arguments, both of which typically change as the algorithm proceeds, it seems reasonable to define a potential function that takes both into account. Let \(x_i\) and \(y_i\) be the values of the two variables in the \(i\)th iteration (recursive call). So, \(x_0 = x\) and \(y_0 = y\), where \(x\) and \(y\) are the original inputs to the algorithm; \(x_1,y_1\) are the arguments to the first recursive call; and so on. As a candidate potential function, we try a simple sum of the two arguments:
Before we look at some examples, let’s first establish that this is a valid potential function. Examining the algorithm, when \(y_i \neq 0\) we see that
where \(r_i = x_i \bmod y_i\). Given the invariant maintained by the algorithm that \(x_i \geq y_i\), and that \(x_i \bmod y_i \in [0, y_i-1]\), we have that \(r_i < y_i \leq x_i\). Therefore,
Thus, the potential \(s\) always decreases by at least one (because \(s\) is a natural number) from one iteration to the next, satisfying the first requirement of a potential function. We also observe that \(y_i \geq 0\) for all \(i\); coupled with \(x_i \geq y_i\), and the fact that both arguments are not zero, we get that \(s_i \geq 1\) for all \(i\). Since we have established a lower bound on \(s\), it meets the second requirement of a potential function.
At this point, we can conclude that Euclid’s algorithm Euclid\((x,y)\) performs at most \(x+y\) iterations. (This is because the initial potential is \(x+y\), each iteration decreases the potential by at least one, and the potential is always greater than zero.) However, this bound is no better than the one we derived for the brute-force GCD algorithm. So, have we just been wasting our time here?
Fortunately, we have not! As we will soon show, this \(x+y\) upper bound for Euclid\((x,y)\) is very loose, and in fact the actual number of iterations is much smaller. We will prove this by showing that the potential decreases much faster than we previously considered.
As an example, let’s look at the values of the potential function for the execution of Euclid\((21, 9)\):
And the following are the potential values for Euclid\((8, 5)\):
The values decay rather quickly for Euclid\((21, 9)\), and somewhat more slowly for Euclid\((8, 5)\). But the key observation is that they appear to decay multiplicatively (by some factor), rather than additively. In these examples, the ratio of \(s_{i+1}/s_i\) is largest for \(s_2/s_1\) in Euclid\((8, 5)\), where it is 0.625. In fact, we will prove an upper bound that is not far from that value.
For all valid inputs \(x,y\) to Euclid’s algorithm, \(s_{i+1} \leq \frac{2}{3} s_i\) for every iteration \(i\) of Euclid\((x, y)\).
The recursive case of Euclid\((x_i, y_i)\) invokes Euclid\((y_i, x_i \bmod y_i)\), so \(x_{i+1} = y_i\) and \(y_{i+1} = r_i = x_i \bmod y_i\) (the remainder of dividing \(x_i\) by \(y_i\)). By definition of remainder, we can express \(x_i\) as
where \(q_i = \floor{x_i/y_i}\) is the integer quotient of \(x_i\) divided by \(y_i\). Since \(x_i \geq y_i\), we have that \(q_i \geq 1\). Then:
We are close to what we need to relate \(s_i\) to \(s_{i+1} = y_i + r_i\), but we would like a common multiplier for both the \(y_i\) and \(r_i\) terms. Let’s split the difference by adding \(r_i/2\) and subtracting \(y_i/2\):
The latter step holds because \(r_i\) is the remainder of dividing \(x_i\) by \(y_i\), so \(y_i - r_i > 0\). (And subtracting a positive number makes a quantity smaller.)
Continuing onward, we have:
Rearranging the inequality, we conclude that \(s_{i+1} \leq \frac{2}{3} s_i\).
By repeated applications of the above lemma (i.e., induction), starting with \(s_0 = x_0 + y_0 = x + y\), we can conclude that:
For all valid inputs \(x,y\) to Euclid’s algorithm, \(s_i \leq \parens{\frac{2}{3}}^i (x + y)\) for all iterations \(i\) of Euclid\((x, y)\).
We can now prove the following:
For any valid inputs \(x,y\), Euclid\((x,y)\) performs \(\O(\log(x + y))\) iterations (and mod operations).
We have previously shown that \(1 \leq s_i \leq \parens{\frac{2}{3}}^i (x + y)\) for the \(i\)th iteration of Euclid\((x,y)\). Therefore,
We have just established an upper bound on \(i\), which means that the number of iterations cannot exceed \(\log_{3/2}(x + y) = \O(\log(x + y))\). Indeed, in order for \(i\) to exceed this quantity, it would have to be the case that \(1 > (2/3)^i (x+y)\), leaving no possible value for the associated potential \(s_i\)—an impossibility! (Also recall that we can change the base of a logarithm by multiplying by a suitable constant, and since \(O\)-notation ignores constant factors, the base in \(\O(\log(x + y))\) does not matter. Unless otherwise specified, the base of a logarithm is assumed to be 2 in this text.) Since each iteration does at most one mod operation, the total number of mod operations is also \(\O(\log(x + y))\), completing the proof.
Under our convention that \(x \geq y\), we have that \(\O(\log(x + y)) = \O(\log 2x) = \O(\log x)\). Recall that the naïve algorithm did \(\Theta(x)\) iterations and mod operations (in the worst case). This means that Euclid’s algorithm is exponentially faster than the naïve algorithm!
We have seen that the potential method gives us an important tool in reasoning about the complexity of algorithms, enabling us to establish an upper bound on the runtime of Euclid’s algorithm.
Divide and Conquer
The divide-and-conquer algorithmic paradigm involves subdividing a large problem instance into smaller instances of the same problem. The subinstances are solved recursively, and then their solutions are combined in some appropriate way to construct a solution for the original larger instance.
Since divide and conquer is a recursive paradigm, the main tool for analyzing divide-and-conquer algorithms is induction. When it comes to complexity analysis, such algorithms generally give rise to recurrence relations expressing the time or space complexity. While these relations can be solved inductively, certain patterns are common enough that higher-level tools have been developed to handle them. We will see one such tool in the form of the master theorem.
As an example of a divide-and-conquer algorithm, the following is a description of the merge sort algorithm for sorting mutually comparable items:
The algorithm sorts an array by first recursively sorting its two halves, then combining the sorted halves with the merge operation. Thus, it follows the pattern of a divide-and-conquer algorithm.

A naïve algorithm such as insertion sort has a time complexity of \(\Theta(n^2)\). How does merge sort compare?
Define \(T(n)\) to be the total number of basic operations (array indexes, element comparisons, etc.) performed by MergeSort on an array of \(n\) elements. Similarly, let \(S(n)\) be the number of basic operations apart from the recursive calls themselves: testing whether \(n=1\), splitting the input array into halves, the cost of Merge on the two halves, etc. Then we have the following recurrence for \(T(n)\):
This is because on an array of \(n\) elements, MergeSort makes two recursive calls to itself on some array of \(n/2\) elements, each of which takes \(T(n/2)\) time by definition, and all its other non-recursive work takes \(S(n)\) by definition. (For simplicity, we ignore the floors and ceilings for \(n/2\), which do not affect the ultimate asymptotic bounds.)
Observe that the merge step does \(n\) comparisons and ~\(n\) array concatenations. Assuming that each of these operations takes a constant amount of time (that does not grow with \(n\)) [2], we have that \(S(n) = \O(n)\). So,
How can we solve this recurrence, i.e., express \(T(n)\) in a “closed form” that depends only on \(n\) (and does not refer to \(T\) itself)? While we can do so using induction or other tools for solving recurrence relations, this can be a lot of work. Thankfully, there is a special tool called the Master Theorem that directly yields a solution to this recurrence and many others like it.
The Master Theorem
Suppose we have some recursive divide-and-conquer algorithm that solves an input of size \(n\):
recursively solving some \(k \geq 1\) smaller inputs,
each of size \(n/b\) for some \(b > 1\) (as before, ignoring floors and ceilings),
where the total cost of all the “non-recursive work” (splitting the input, combining the results, etc.) is \(\O(n^d)\).
Then the running time \(T(n)\) of the algorithm follows the recurrence relation
The Master Theorem provides the solutions to such recurrences. [3]
Let \(k \geq 1, b > 1, d \geq 0\) be constants that do not vary with \(n\), and let \(T(n)\) be a recurrence with base case \(T(1)=O(1)\) having the following form, ignoring ceilings/floors on (or more generally, addition/subtraction of any constant to) the \(n/b\) argument on the right-hand side:
Then this recurrence has the solution
In addition, the above bounds are tight: if the \(\O\) in the recurrence is replaced with \(\Theta\), then it is in the solution as well.
Observe that the test involving \(k\), \(b\), and \(d\) can be expressed in logarithmic form, by taking base-\(b\) logarithms and comparing \(\log_b k\) to \(d\).
In the case of merge sort, we have \(k=b=2\) and \(d = 1\), so \(k = b^d\), so the solution is \(T(n) = \O(n \log n)\) (and this is tight). Thus, merge sort is much more efficient than insertion sort! (As always in this text, this is merely an asymptotic statement, for large enough \(n\).)
We emphasize that in order to apply (this version of) the Master Theorem, the values \(k, b, d\) must be constants that do not vary with \(n\). For example, the theorem does not apply to a divide-and-conquer algorithm that recursively solves \(k = \sqrt{n}\) subinstances, or one whose subinstances are of size \(n/\log n\). In such a case, a different tool is needed to solve the recurrence. Fortunately, the Master Theorem does apply to the vast majority of divide-and-conquer algorithms of interest.
Master Theorem with Log Factors
A recurrence such as
\[T(n) = 2 T(n/2) + \O(n \log n)\]
does not exactly fit the form of the master theorem above, since the additive term \(\O(n \log n)\) does not look like \(\O(n^d)\) for some constant \(d\). [4] Such a recurrence can be handled by a more general form of the theorem, as follows.
Let \(T(n)\) be the following recurrence, where \(k \geq 1, b > 1, d \geq 0, w \geq 0\) are constants that do not vary with \(n\):
Then:
Applying the generalized master theorem to the recurrence
\[T(n) = 2T(n/2) + \O(n \log n) \; \text,\]
we have \(k = 2, b = 2, d = 1, w = 1\), so \(k = b^d\). Therefore,
\[\begin{split}T(n) &= \O(n^d \log^{w+1} n) \\ &= \O(n \log^2 n) \; \text.\end{split}\]
Integer Multiplication
We now turn our attention to algorithms for integer multiplication. For fixed-size data types, such as 32-bit integers, multiplication can be done in a constant amount of time, and is typically implemented as a hardware instruction for common sizes. However, if we are working with arbitrary \(n\)-bit numbers, we will have to implement multiplication ourselves in software. (As we will see later, multiplication of such “big” integers is essential to many cryptography algorithms.)
Let’s first take a look the standard grade-school long-multiplication algorithm.

Here, the algorithm is illustrated for binary numbers, but it works the same as for decimal numbers, just in base two. We first multiply the top number by the last (least-significant) digit in the bottom number. We then multiply the top number by the second-to-last digit in the bottom number, but we shift the result leftward by one digit. We repeat this for each digit in the bottom number, adding one more leftward shift with each digit. Once we have done all the multiplications for each digit of the bottom number, we add up the results to compute the final product.
How efficient is this algorithm? If the input numbers are each \(n\) bits long, then each individual multiplication takes linear \(\O(n)\) time: we have to multiply each digit in the top number by the single digit in the bottom number (plus a carry if we are working in decimal). Since we have to do \(n\) multiplications, computing the partial results takes \(\O(n^2)\) total time. We then need to add the \(n\) partial results. The longest partial result is the last one, which is about \(2n\) digits long. Thus, we add \(n\) numbers, each of which has \(\O(n)\) digits. Adding two \(\O(n)\)-digit numbers takes \(\O(n)\) time, so adding \(n\) of them takes a total of \(\O(n^2)\) time. Adding the time for the multiplications and additions leaves us with a total of \(\O(n^2)\) time for the entire multiplication. (All of the above bounds are tight, so the running time is in fact \(\Theta(n^2)\).)
Can we do better? Let’s try to make use of the divide-and-conquer paradigm. We first need a way of breaking up an \(n\)-digit number into smaller pieces. We can do that by splitting it into the first \(n/2\) digits and the last \(n/2\) digits. For the rest of our discussion, we will work with decimal numbers, though the same reasoning applies to numbers in any other base. Assume that \(n\) is even for simplicity (we can ensure this by appending a zero in the most-significant digit, if needed).

As an example, consider the number 376280. Here \(n = 6\), and splitting the number into two pieces gives us 376 and 280. How are these pieces related to the original number? We have:
In general, when we split an \(n\)-digit number \(X\) into two \(n/2\)-digit pieces \(A\) and \(B\), we have that \(X = A\cdot 10^{n/2} + B\).
Let’s now apply this splitting process to multiply two \(n\)-digit numbers \(X\) and \(Y\). Split \(X\) into \(A\) and \(B\), and \(Y\) into \(C\) and \(D\), so that:

We can then expand \(X \cdot Y\) as:
This suggests a natural divide-and-conquer algorithm for multiplying \(X\) and \(Y\):
split them as above,
recursively multiply \(A \cdot C\), \(A \cdot D\), etc.,
multiply each of these by the appropriate power of 10,
sum everything up.
How efficient is this computation? First, observe that multiplying a number by \(10^k\) is the same as shifting it to the left by appending \(k\) zeros to the (least-significant) end of the number, so it can be done in \(\O(k)\) time. So, the algorithm has the following subcomputations:
4 recursive multiplications of \(n/2\)-digit numbers (\(A \cdot C\), \(A \cdot D\), \(B \cdot C\), \(B \cdot D\)),
2 left shifts, each of which takes \(\O(n)\) time,
3 additions of \(\O(n)\)-digit numbers, which take \(\O(n)\) time.
Let \(T(n)\) be the time it takes to multiply two \(n\)-digit numbers using this algorithm. By the above analysis, it satisfies the recurrence
Applying the Master Theorem with \(k = 4\), \(b = 2\), \(d = 1\), we have that \(k > b^d\). Therefore, the solution is
Unfortunately, this is the same as for the long-multiplication algorithm! We did a lot of work to come up with a divide-and-conquer algorithm, and it doesn’t do any better than a naïve algorithm. Our method of splitting and recombining wasn’t sufficiently “clever” to yield an improvement.
The Karatsuba Algorithm
Observe that the \(\O(n^2)\) bound above has an exponent of \(\log_2 4 = 2\) because we recursed on four separate subinstances of size \(n/2\). Let’s try again, but this time, let’s see if we can rearrange the computation so that we have fewer than four such subinstances. We previously wrote
This time, we will write \(X \cdot Y\) in a different, more clever way using fewer multiplications of (roughly) “half-size” numbers. Consider the values
Observe that \(M_1 = A \cdot C + A \cdot D + B \cdot C + B \cdot D\), and we can subtract \(M_2 = A \cdot C\) and \(M_3 = B \cdot D\) to obtain
This is exactly the “middle” term in the above expansion of \(X \cdot Y\). Thus:
This suggests a different divide-and-conquer algorithm for multiplying \(X\) and \(Y\):
split them as above,
compute \(A+B, C+D\) and recursively multiply them to get \(M_1\),
recursively compute \(M_2 = A \cdot C\) and \(M_3 = B \cdot D\),
compute \(M_1 - M_2 - M_3\),
multiply by appropriate powers of 10,
sum up the terms.
This is known as the Karatsuba algorithm. How efficient is the computation? We have the following subcomputations:
Computing \(M_1\) does two additions of \(n/2\)-digit numbers, resulting in two numbers that are up to \(n/2+1\) digits each. This takes \(\O(n)\) time.
Then these two numbers are multiplied, which takes essentially \(T(n/2)\) time. (The Master Theorem lets us ignore the one extra digit of input length, just like we can ignore floors and ceilings.)
Computing \(M_2\) and \(M_3\) each take \(T(n/2)\) time.
Computing \(M_1 - M_2 - M_3\), multiplying by powers of 10, and adding up terms all take \(\O(n)\) time.
So, the running time \(T(n)\) satisfies the recurrence
Applying the master theorem with \(k = 3\), \(b = 2\), \(d = 1\), we have that \(k > b^d\). This yields the solution
(Note that \(\log_2 3\) is slightly smaller than \(1.585\), so the second equality is valid because big-O represents an upper bound.) Thus, the Karatsuba algorithm gives us a runtime that is asymptotically much faster than the naïve algorithm! Indeed, it was the first algorithm discovered for integer multiplication that takes “subquadratic” time.
The Closest-Pair Problem
In the closest-pair problem, we are given \(n \geq 2\) points in \(d\)-dimensional space, and our task is to find a pair \(p,p'\) of the points whose distance apart \(\length{p-p'}\) is smallest among all pairs of the points; such points are called a “closest pair”. Notice that there may be ties among distances between points, so there may be more than one closest pair. Therefore, we typically say a closest pair, rather than the closest pair, unless we know that the closest pair is unique in some specific situation. This problem has several applications in computational geometry and data mining (e.g. clustering). The following is an example of this problem in two dimensions, where the (unique) closest pair is at the top left in red.

A naïve algorithm compares the distance between every pair of points and returns a pair that is the smallest distance apart; since there are \(\Theta(n^2)\) pairs, the algorithm takes \(\Theta(n^2)\) time. Can we do better?
Let’s start with the problem in the simple setting of one dimension. That is, given a list of \(n\) real numbers \(x_1, x_2, \ldots, x_n\), we wish to find a pair of the numbers that are closest together. In other words, find some \(x_i,x_j\) that minimize \(\abs{x_i - x_j}\), where \(i \ne j\).
Rather than comparing every pair of numbers, we can first sort the numbers. Then it must be the case that there is some closest pair of numbers that is adjacent in the sorted list. (Exercise: prove this formally. However, notice that not every closest pair must be adjacent in the sorted list, because there can be duplicate numbers.) So, we need only compare each pair of adjacent points to find some closest pair. The following is a complete algorithm:
As we saw previously, merge sort takes \(\Theta(n \log n)\) time (assuming fixed-size numbers). The algorithm above also iterates over the sorted list, doing a constant amount of work in each iteration. This takes \(\Theta(n)\) time. Putting the two steps together results in a total running time of \(\Theta(n \log n)\), which is better than the naïve \(\Theta(n^2)\).
This algorithm works for one-dimensional points, i.e., real numbers. Unfortunately, it is not clear how to generalize this algorithm to two-dimensional points. While there are various ways we can sort such points, there is no obvious ordering that provides the guarantee that some closest pair of points is adjacent in the resulting ordering. For example, if we sort by \(x\)-coordinate, then a closest pair will be relatively close in their \(x\)-coordinates, but there may be another point with an \(x\)-coordinate between theirs that is very far away in its \(y\)-coordinate.
Let’s take another look at the one-dimensional problem, instead taking a divide-and-conquer approach. Consider the median of all the points, and suppose we partition the points into two halves of (almost) equal size, according to which side of the median they lie on. For simplicity, here and below we assume without loss of generality that the median splits the points into halves that are as balanced as possible, by breaking ties between points as needed to ensure balance.

Now consider a closest pair of points in the full set. It must satisfy exactly one of the following three cases:
both points are from the left half,
both points are from the right half,
it “crosses” the halves, with one point in the left half and the other point in the right half.
In the “crossing” case, we can draw a strong conclusion about the two points: they must consist of a largest point in the left half, and a smallest point in the right half. (For if not, there would be an even closer crossing pair, which would contradict the hypothesis about the original pair.) So, such a pair is the only crossing pair we need to consider when searching for a closest pair.
This reasoning leads naturally to a divide-and-conquer algorithm. We find the median and recursively find a closest pair within just the left-half points, and also within just the right-half points. We also consider a largest point on the left with a smallest point on the right. Finally, we return a closest pair among all three of these options. By the three cases above, the output must be a closest pair among all the points. Specifically, in the first case, the recursive call on the left half returns a closest pair for the full set, and similarly for the second case and the recursive call on the right half. And in the third case, by the above reasoning, the specific crossing pair constructed by the algorithm is a closest pair for the full set.
The full algorithm is as follows. For the convenience of the recursive calls, in the case \(n=1\) we define the algorithm to return a “dummy” output \((\bot,\bot,\infty)\) representing non-existent points that are infinitely far apart. Therefore, we do not have to check whether each recursive call involves more than one point, and some other pair under consideration will be closer than this dummy result.
Analyzing this algorithm for its running time, we can find the median of a set of points by sorting them and then taking the point in the middle. We can also obtain a largest element in the left side and a largest element in the right right from the sorted list. Partitioning the points by the median also takes \(\Theta(n)\) time; we just compare each point to the median. The non-recursive work is dominated by the \(\Theta(n \log n)\)-time sorting, so we end up with the recurrence:
This isn’t quite covered by the basic form of the Master Theorem, since the additive term is not of the form \(\Theta(n^d)\) for a constant \(d\). However, it is covered by the Master Theorem with Log Factors, which yields the solution \(T(n) = \Theta(n \log^2 n)\). (See also a solution using substitution in Example 298.) This means that this algorithm is asymptotically less efficient than our previous one! However, there are two possible modifications we can make:
Use a \(\Theta(n)\) median-finding algorithm rather than sorting to find the median.
Sort the points just once at the beginning, so that we don’t need to re-sort in each recursive call.
Either modification brings the running time of the non-recursive work down to \(\Theta(n)\), resulting in a full running time of \(T(n) = \Theta(n \log n)\). (The second option involves an additional \(\Theta(n \log n)\) on top of this for the presorting, but that still results in a total time of \(\Theta(n \log n)\).)
In the one-dimensional closest-pair algorithm, we computed the median \(m\), the closest-pair distance \(\delta_L\) on the left, and the closest-pair distance \(\delta_R\) on the right. Let \(\delta = \min \set{\delta_L, \delta_R}\). How many points can lie in the interval \([m, m + \delta)\)? What about the interval \((m - \delta, m + \delta)\)?

Now let’s try to generalize this algorithm to two dimensions. It’s not clear how to split the points according to a median point, or even what a meaningful “median point” would be. So rather than doing that, we instead use a median line as defined by the median \(x\)-coordinate.

As before, any closest pair for the full set must satisfy one of the following: both of its points are in the left half, both are in the right half, or it is a “crossing” pair with exactly one point in each half. Similarly to above, we will prove that in the “crossing” case, the pair must satisfy some specific conditions. This means that it will suffice for our algorithm to check only those crossing pairs that meet the conditions—since this will find a closest pair, it can ignore all the rest.
In two dimensions we cannot draw as strong of a conclusion about the “crossing” case as we could in one dimension. In particular, the \(x\)-coordinates of the pair may not be closest to the median line: there could be another crossing pair whose \(x\)-coordinates are even closer to the median line, but whose \(y\)-coordinates are very far apart, making that pair farther apart overall. Nevertheless, the \(x\)-coordinates are “relatively close” to the median line, as shown in the following lemma.
Let \(\delta_L\) and \(\delta_R\) respectively be the closest-pair distances for just the left and right halves. If a closest pair for the entire set of point is “crossing,” then both of its points must be within distance \(\delta = \min \set{\delta_L, \delta_R}\) of the median line.
We prove the contrapositive. If a crossing pair of points has at least one point at distance greater than \(\delta\) from the median line, then the pair of points are more than \(\delta\) apart. Therefore, they cannot be a closest pair for the entire set, because there is another pair that is only \(\delta\) apart.
Thus, the only crossing pairs that our algorithm needs to consider are those whose points lie in the “\(\delta\)-strip”, i.e., the space within distance \(\delta\) of the median line (in the \(x\)-coordinate); no other crossing pair can be a closest pair for the entire set. This leads to the following algorithm:
Apart from its checks of crossing pairs in the \(\delta\)-strip, the non-recursive work is same as in the one-dimensional algorithm, and it takes \(\Theta(n)\) time. (We can presort the points by \(x\)-coordinate or use a \(\Theta(n)\)-time median-finding algorithm, as before.) How long does it take to check the crossing pairs in the \(\delta\)-strip? A naïve examination would consider every pair of points where one is in the left side of the \(\delta\)-strip and the other is in its right side. But notice that in the worst case, all of the points can be in the \(\delta\)-strip! For example, this can happen if the points are close together in the \(x\)-dimension—in the extreme, they all lie on the median line—but far apart in the \(y\)-dimension. So in the worst case, we have \(n/2\) points in each of the left and right parts of the \(\delta\)-strip, leaving us with \(n^2/4 = \Theta(n^2)\) crossing pairs to consider. So we end up with the recurrence and solution
This is no better than the naïve algorithm that just compares all pairs of points! We have not found an efficient enough non-recursive “combine” step.
Let’s again consider the case where a closest pair for the whole set is a “crossing” pair, and try to establish some additional stronger properties for it, so that our algorithm will not need to examine as many crossing pairs in its combine step. Let \(p_L = (x_L, y_L)\) and \(p_R = (x_R, y_R)\) respectively be the points from the pair that are on the left and right of the median line, and assume without loss of generality that \(y_L \geq y_R\); otherwise, replace \(p_L\) with \(p_R\) in the following analysis. Because this is a closest pair for the entire set of points, \(p_L\) and \(p_R\) are at most \(\delta = \min\set{\delta_L, \delta_R}\) apart, where as in Lemma 20 above, \(\delta_L\) and \(\delta_R\) are respectively the closest-pair distances for just the left and right sides. Therefore, \(0 \leq y_L-y_R \leq \delta\).

We ask: how many of the given points \(p' = (x',y')\) in the \(\delta\)-strip can satisfy \(0 \leq y_L-y' \leq \delta\)? Equivalently, any such point is in the \(\delta\)-by-\(2\delta\) rectangle of the \(\delta\)-strip whose top edge has \(p_L\) on it. We claim that there can be at most eight such points, including \(p_L\) itself. (The exact value of eight is not too important; what matters is that it is a constant.) The key to the proof is that every pair of points must be at least \(\delta\) apart, so we cannot fit too may points into the rectangle. We leave the formal proof to Exercise 25 below.
In conclusion, we have proved the following key structural lemma.
If a closest pair for the whole set is a crossing pair, then its two points are in the \(\delta\)-strip, and they are within 7 positions of each other when all the points in the \(\delta\)-strip are sorted by \(y\)-coordinate.
So, if a closest pair in the whole set is a crossing pair, then it suffices for the algorithm to compare each point in the \(\delta\)-strip with the (up to) seven points in the \(\delta\)-strip that precede it in sorted order by \(y\)-coordinate. By Lemma 23, this will find a closest pair for the entire set, so the algorithm does not need to check any other pairs. The formal algorithm is as follows.
We have already seen that we can presort by \(x\)-coordinate, so that finding the median and constructing \(L,R\) in each run of the algorithm takes just \(O(n)\) time. We can also separately presort by \(y\)-coordinate (into a different array) so that we do not have to sort the \(\delta\)-strip in each run. Instead, we merely filter the points from the presorted array according to whether they lie within the \(\delta\)-strip, which also takes \(O(n)\) time. Finally, we consider at most \(7n = \Theta(n)\) pairs in the \(\delta\)-strip. So, the non-recursive work takes \(\Theta(n)\) time, resulting in the runtime recurrence and solution
This matches the asymptotic efficiency of the one-dimensional algorithm. The algorithm can be further generalized to higher dimensions, retaining the \(\Theta(n \log n)\) runtime for any fixed dimension.
Prove that any \(\delta\)-by-\(2\delta\) rectangle of the \(\delta\)-strip can have at most 8 of the given points, where \(\delta\) is as defined in Lemma 20.
Specifically, prove that the left \(\delta\)-by-\(\delta\) square of the rectangle can have at most four of the points (all from left subset), and similarly for the right square.
Hint: Partition each square into four congruent sub-squares, and show that each sub-square can have at most one point (from the relevant subset).
Dynamic Programming
The idea of subdividing a large problem instance into smaller instances of the same problem lies at the core of the divide-and-conquer paradigm. However, for some problems, this recursive subdivision may result in many recoccurences of the exact same subinstance. Such situations are amenable to the paradigm of dynamic programming, which is applicable to problems that have the following features:
The principle of optimality, also known as an optimal substructure. This means that an optimal solution to a larger instance is made up of optimal solutions to smaller subinstances. For example, shortest-path problems on graphs generally obey the principle of optimality. If a shortest path between vertices \(a\) and \(b\) in a graph goes through some other vertex \(c\), so that the path has the form \(a, u_1, \ldots, u_j, c, v_1, \dots, v_k, b\), then the subpath \(a, u_1, \ldots, u_j, c\) must be a shortest path from \(a\) to \(c\), and similarly for the subpath from \(c\) to \(b\).
Overlapping subinputs/subproblems. This means that the same input occurs many times when recursively decomposing the original instance down to the base cases. A classic example of this is a recursive computation of the Fibonacci sequence, which follows the recurrence \(F(n) = F(n-1) + F(n-2)\). The same subinstances appear over and over again, making a naïve computation takes time exponential in \(n\). The characteristic of overlapping subinputs is what distinguishes dynamic programming from divide and conquer.

Implementation Strategies
The first, and typically most challenging and creative, step in formulating a dynamic-programming solution to a problem is to determine a recurrence relation that solutions adhere to. In the case of the Fibonacci sequence, for example, such a recurrence (and base cases) are already given, as:
Once we have established a recurrence relation and base cases, we can turn to an implementation strategy for computing the desired value(s) of the recurrence. There are three typical patterns:
Top-down recursive. The naïve implementation directly translates the recurrence relation into a recursive algorithm, as in the following:
Algorithm 26 (Top-down Fibonacci)As mentioned previously, the problem with this strategy is that it repeats the same computations many times, to the extent that the overall number of recursive calls is exponential in \(n\). More generally, naïve top-down implementations are wasteful when there are overlapping subinputs. (They do not use any auxiliary storage, so they are space efficient, but this is usually outweighed by their poor running times. [5])
Top-down memoized, or simply memoization. This approach also translates the recurrence relation into a recursive algorithm, but it saves every computed result in a lookup table, and queries that table before doing any new computation. The following is an example:
Algorithm 27 (Memoized Fibonacci)This memoized algorithm avoids recomputing the answer for any previously encountered input. Any call to FibMemoized\((n)\), where \(n\) is not a base case, first checks the memo table to see if FibMemoized\((n)\) has been computed before. If not, it computes it recursively as above, saving the result in memo. If the subinput was previously encountered, the algorithm just returns the previously computed result.
Memoization trades space for time. The computation of FibMemoized\((n)\) requires \(\O(n)\) auxiliary space to store the results for each subinput. On the other hand, since the answer to each subinput is computed only once, the overall number of operations required is \(\O(n)\), a significant improvement over the exponential naïve algorithm. However, for more complicated algorithms, it can be harder to analyze the running time of the associated algorithm.
Bottom up. [6] Rather than starting with the desired input and recursively working our way down to the base cases, we can invert the computation to start with the base case(s), and then work our way up to the desired input. As in recursion with memoization, we need a table to store the results for the subinputs we have handled so far, since those results will be needed to compute answers for larger inputs.
The following is a bottom-up implementation for computing the Fibonacci sequence:
Algorithm 28 (Bottom-up Fibonacci)We start with an empty table and populate it with the results for the base cases. Then we work our way forward, computing the result for each larger input from the previously computed results for the smaller inputs. We stop when we reach the desired input, and return the result. The following is an illustration of the table that is constructed during the computation of FibBottomUp\((9)\).

In the loop for a particular value of \(i\), earlier iterations have already computed and stored the \((i-1)\)st and \((i-2)\)nd Fibonacci numbers—stored in \(\tabl[i-1]\) and \(\tabl[i-2]\), respectively—so the algorithm just looks up those results from the table and adds them to get the \(i\)th Fibonacci number, which it stores in \(\tabl[i]\).
Like memoization, the bottom-up approach trades space for time. In the case of FibBottomUp\((n)\), it too uses a total of \(n\) array entries to store the results of the subinstances, and the overall number of additions required is also less than \(n\).
In the specific case of computing the Fibonacci sequence, we don’t actually need to keep the entire table for the entire computation: once we are computing the \(i\)th Fibonacci number, we no longer need the \((i-3)\)rd table entry or lower. So, at any moment we need only keep the two previously computed results. This lowers the storage overhead to just \(\O(1)\) entries. However, this kind of space savings doesn’t work in general for dynamic programming; other problems require maintaining most or all of the table throughout the computation.
The three implementation strategies have different tradeoffs. The naïve top-down strategy often takes the least implementation effort, as it is a direct translation of the recurrence relation to code. It can be the most space efficient (though including the space used by the recursive call stack complicates the comparison), but more importantly, it often is very inefficient in time, due to the many redundant computations.
Top-down recursion with memoization adds some implementation effort in working with a lookup table, and can require special care to implement correctly and safely in practice. [7]
Its main advantages over the bottom-up approach are:
It maintains the same structure as the recurrence relation, so it typically is simpler to reason about and implement.
It computes answers for only the subinputs that are actually needed. If the recurrence induces a “sparse” computation, meaning that it requires answers for relatively few of the smaller subinputs, then the top-down memoization approach can be more time and space efficient than the bottom-up strategy.
However, top-down memoization often suffers from higher constant-factor overheads than the bottom-up approach (e.g., function-call overheads and working with sparse lookup structures that are less time efficient than dense data structures). Thus, the bottom-up approach is preferable when answers to a large fraction of the subinstances are needed for computing the desired result, which is usually the case for dynamic programming problems.
Weighted Task Selection
As a first nontrivial example of dynamic programming, let us consider a problem called weighted task selection (WTS). In this problem, we are given a list of \(n\) tasks \(T_1,\ldots,T_n\). Each task \(T_i\) is a triple of numbers \((s_i,f_i,v_i)\) with \(s_i < f_i\), where \(s_i\) denotes the task’s starting time, \(f_i\) denotes its finishing time, and \(v_i\) denotes its value. A pair of tasks \(T_i, T_j\) overlap if \(s_i \leq s_j < f_i\) or \(s_j \leq s_i < f_j\), i.e., if the intersection of their time intervals \([s_i, f_i) \cap [s_j,f_j)\) is nonempty. The goal in WTS is to select an optimal set of (pairwise) non-overlapping tasks, which is one that maximizes the total value of the selected tasks.
Note that there may be multiple different sets that have the same optimal value, so we say “an” optimal set, rather than “the” optimal set. Throughout this treatment it is convenient to assume without loss of generality that the tasks are sorted by their finish times \(f_i\) (which are not necessarily distinct); in particular, we can sort them in \(O(n \log n)\) time.
The figure below shows an example instance of the WTS problem with eight tasks. The set \(\set{T_5,T_7}\) has a large total value of \(13+10=23\), but it is overlapping, so it cannot be selected. The set \(\set{T_1,T_5,T_6}\) is not overlapping, and has a total value of \(5+13+2 = 20\), but it turns out that this is not optimal. An optimal set of tasks is \(\set{T_1,T_3,T_7}\), and has a total value of \(5+7+10 = 22\). In fact, in this case it is the unique optimal set (but again, in general an optimal set will not be unique).

This problem models various situations including scheduling of jobs on a single machine, choosing courses to take, etc. So it is indeed useful, but can we solve it efficiently?
The design and analysis of a dynamic programming algorithm usually follows the following template, or “recipe”, of steps:
Define and focus on the “value version” of the problem. For an optimization problem like WTS, temporarily put aside the goal of finding an optimal solution itself, and simply aim to find the value of an optimal solution (e.g., the lowest cost, the largest total value, etc.). In some cases, the original problem is already stated in a value version—e.g., count the number of objects meeting certain constraints—so there is nothing to do in this step.
Devise a recurrence for the value in question, including base case(s), by understanding how a solution is made up of solutions to appropriate subinputs. This step usually requires some creativity and insight, both to discover a good set of relevant subinputs, and to see how optimal solutions are related across subinputs.
By understanding the dependencies between subinputs as given by the recurrence, implement the recurrence in (pseudo)code that fills a table in a bottom-up fashion. Given the recurrence, this step is usually fairly “mechanical” and does not require a great deal of creativity.
If applicable, extend the pseudocode to solve the original problem using “backtracking”. Given the recurrence and an understanding of why it is correct, this is also usually quite mechanical.
Perform a runtime analysis of the algorithm. This is also usually fairly mechanical, and follows from analyzing the number of table entries that are filled, and the amount of time it takes to fill each entry (or in some cases, all the entries in total).
Notice that all steps but the second one are fairly mechanical, but they rely crucially on the recurrence derived in that step.
For example, for the above example instance of our task-selection problem, we first want to focus on designing an algorithm that simply computes the optimal value 22, instead of directly computing an optimal set of non-overlapping tasks \(\set{T_1,T_3,T_7}\). As we will see, a small enhancement of the value-optimizing algorithm will also give us a selection of tasks that achieves the optimal value, so we actually lose nothing by initially focusing on the value alone. To do this, we first need to come up with a recurrence that yields the optimal value for a given set of tasks.
For \(0 \leq i \leq n\), let \(\OPT(i)\) denote the optimal value that can be obtained by selecting from among just the tasks \(T_1,\dots,T_i\). The base case is \(i=0\), for which the optimal value is trivially \(\OPT(0)=0\), because there are no tasks available to select. Now suppose that \(i \geq 1\), and consider task \(T_i\) (which has the latest finish time among those we are considering). There are two possibilities: either \(T_i\) is in some optimal selection of tasks (from just \(T_1,\ldots,T_i\)), or it is not.
If \(T_i\) is not in an optimal selection, then \(\OPT(i) = \OPT(i-1)\). This is because there is an optimal selection for all \(i\) tasks that selects from just the first \(i-1\) tasks, so the availability of \(T_i\) does not affect the optimal value.
If \(T_i\) is in an optimal solution, then \(\OPT(i) = v_i + \OPT(j)\), where \(j < i\) is the maximum index such that \(T_j\) and \(T_i\) do not overlap, i.e., \(f_j \leq s_i\) (taking \(j=0\) if no such \(T_j\) exists). This is because in any optimal selection \(S\) that has \(T_i\), the other selected tasks must come from \(T_1, \ldots, T_j\) (because these are the tasks that don’t overlap with \(T_i\)), and those selected tasks must have optimal value (among the first \(j\) tasks). For if they did not, we could replace them with a higher-value selection from \(T_1, \ldots, T_j\), then include \(T_i\) to get a valid selection of tasks with a higher value than that of \(S\), contradicting the assumed optimality of \(S\).
Overall, the optimal value is the maximum of what can be obtained from these two possibilities. Therefore, we obtain the final recurrence as follows, for all \(i \geq 1\):
\[\OPT(i) = \max \set{ \OPT(i-1), v_i + \OPT(j) } \; \text{ for the maximum $j < i$ s.t. } f_j \leq s_i \; \text.\]
To ensure that such a \(j\) is always defined, we adopt the convention that \(f_0 = -\infty\), so that \(j=0\) is an option (in which case the second value in the above \(\max\) expression is just \(v_i + \OPT(0) = v_i\)).
Now that we have a recurrence, we can write pseudocode that implements it by filling a table in a bottom-up manner.
A naïve implementation of this algorithm, which just does a linear scan inside the loop to determine \(j\), takes \(O(n^2)\) time because there are two nested loops that each take at most \(n\) iterations. Since the tasks are sorted by finish time, a more sophisticated implementation would use a binary search, which would take just \(O(\log n)\) time for the inner (search) loop, and hence \(O(n \log n)\) time overall. (Recall that the initial time to sort the tasks by finish time is also \(O(n \log n)\).)
For a better understanding of this algorithm, let us see the filled table for the example instance given above. We see that indeed \(\OPT(n) = \OPT(8) = 22\), which is the correct answer. (We can also observe that entry \(7\) of the table is also \(22\), indicating that there is a globally optimal selection from among just the first \(7\) tasks.)
Index \(i\) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|---|---|---|---|---|---|---|---|---|---|
\(\OPT(i)\) |
0 |
5 |
5 |
12 |
16 |
18 |
20 |
22 |
22 |
Now that we have an efficient algorithm for the value version of the problem, let us see how to solve the problem we actually care about, which is to obtain an optimal selection of tasks. The idea is to keep some additional information showing “why” each entry of the table has the value it does, and to construct an optimal selection by “backtracking” through the table. That is, we enhance the algorithm to add “pointers” (sometimes called “breadcrumbs”) that store how each cell in the table was filled, based on the recurrence and the values of the previous cells.
To carry out this approach for our problem, we will add pointers, denoted by \(\backtrack[i]\), into our algorithm. When we fill in \(\tabl[i]\), we also set \(\backtrack[i] = i-1\) if we set \(\tabl[i] = \tabl[i-1]\), otherwise we set \(\backtrack[i] = j\) where \(j\) is defined as in the recurrence and algorithm. Recalling the reasoning for why the recurrence is valid, these two possibilities respectively correspond to task \(T_i\) not being in, or being in, an optimal subset of tasks from \(T_1,\ldots,T_i\). The value of \(\backtrack[i]\) indicates the prefix of tasks from which the rest of that optimal subset is drawn.
Given the two arrays \((\tabl,\backtrack)\), we can now construct an optimal set of tasks, not just the optimal value. Start with index \(i = n\). Recall that \(\tabl[i] > \tabl[i-1]\) if and only if \(T_i\) is in some optimal selection of tasks. So, if \(\tabl[i] > \tabl[i-1]\), then we include \(T_i\) in the output selection, otherwise we skip it. We then “backtrack” by setting \(i = \backtrack[i]\) to consider the appropriate prefix of tasks, and repeat this process until we have backtracked to the beginning.
The modified full pseudocode, including the backtracking, can be seen below.
Longest Increasing Subsequence
Given a sequence \(S\) of numbers, an increasing subsequence of \(S\) is a subsequence whose elements are in strictly increasing order. As with a subsequence of a string, the elements need not be contiguous in the original sequence, but they must be taken in their original order.
Now suppose we want to find a longest increasing subsequence (LIS) of a given input sequence \(S\), i.e., an increasing subsequence with the maximum number of values in it. As in the task-selection problem, we say “an” LIS, rather than “the” LIS, because an LIS may not be unique. For example, the sequence \(S = (0, 8, 7, 12, 5, 10, 4, 14, 3, 6)\) has several longest increasing subsequences:
\((0, 8, 12, 14)\),
\((0, 8, 10, 14)\),
\((0, 7, 12, 14)\),
\((0, 7, 10, 14)\),
\((0, 5, 10, 14)\).
As in the previous problem of task selection, before concerning ourselves with finding an LIS itself, we first devise a suitable “value version” of the problem and a recurrence for it. As a first attempt, let the input sequence be \(S[1,\ldots,N]\), and consider the subproblems of computing the LIS length for each prefix sequence \(S[1,\ldots,i]\), for \(i = 1,\ldots,N\). For the example of \(S = (0, 8, 7, 12, 5, 10, 4, 14, 3, 6)\), we can determine these LIS lengths by hand.

Unfortunately, it is not clear how to relate the LIS length for a sequence to the LIS lengths for its prefixes. In the example above, \(S[1,\ldots,9]\) and \(S[1,\ldots,10]\) have the same LIS length, but that is not the case for \(S[1,\ldots,7]\) and \(S[1,\ldots,8]\). Yet in both cases, the one additional element is larger than the previous one in the sequence (i.e., \(S[10] > S[9]\) and \(S[8] > S[7]\)). It seems that, without knowing something about the contents of an LIS itself (and not just the LIS length), it is unclear how the LIS length for a sequence is related to those for its prefixes.
In order to devise a dynamic-programming solution for the LIS problem, we need to formulate a “value version” of the problem that satisfies the optimal-substructure property. A clever idea that turns out to work is to restrict our view to subsequences of \(S[1,\ldots,i]\) that include the last element \(S[i]\). More specifically, for any \(i \geq 1\), define \(\ENDLIS(i)\) to be the length of any longest increasing subsequence of \(S[1,\ldots,i]\) that includes (and therefore ends with) \(S[i]\). As we will see next, this restriction is just enough information about the contents of an LIS to satisfy the optimal-substructure property, and thereby derive a useful recurrence.
For both the base case and recursive cases, it is convenient to define a “sentinel” value of \(S[0]=-\infty\). This element can be seen as the initial “placeholder” element in any LIS of any prefix \(S[1,\ldots,i]\), but it does not contribute to the length. With this convention, in the base case \(i=0\) we trivially have \(\ENDLIS(0)=0\), because the only possible subsequence consists merely of \(S[0]\), which has length zero.
We next derive a recurrence for \(\ENDLIS(i)\) for any \(i \geq 1\), by establishing an “optimal substructure” property for longest increasing subsequences.
Let \(L\) be any LIS of \(S[1,\ldots,i]\) that ends with \(S[i]\), and let \(L'\) be \(L\) with this last element removed. Then the last element of \(L'\) (which might be the sentinel value \(S[0]\)) must be \(S[j]\) for some \(0 \leq j < i\) where \(S[j] < S[i]\), because \(L\) is an increasing subsequence of \(S\).
We claim that \(L'\) must be an LIS of \(S[1,\ldots,j]\) that ends with \(S[j]\). For if it is not, then there would exist some increasing subsequence \(L^*\) of \(S[1,\ldots,j]\) that ends with \(S[j] < S[i]\), and is longer than \(L'\). Then, \(L^*\) followed by \(S[i]\) would be an increasing subsequence of \(S[1,\ldots,i]\) that ends with \(S[i]\), and is longer than \(L\) (because \(L^*\) is longer than \(L'\)). But this would contradict our initial hypothesis, that \(L\) is a longest such subsequence! So, such a \(L^*\) cannot exist, and the claim is proved.
In what we have just shown, there is no restriction on the value of \(0 \leq j < i\), other than the requirement that \(S[j] < S[i]\). Indeed, for any such \(j\), any LIS of \(S[1,\ldots,j]\) that ends with \(S[j]\) can be extended, by appending \(S[i]\), into an LIS of \(S[1,\ldots,i]\) that ends with \(S[i]\). Therefore, \(\ENDLIS(i)\) is one larger than the largest of all these options, taken over all valid \(j\). In summary, we have proved the following base case and recurrence for \(\ENDLIS\):
The following gives the values of this recurrence for the example sequence \(S\) above, and also shows which values are referenced when evaluating \(\ENDLIS(10)\) according to the recurrence.

Using the above recurrence, we can straightforwardly write a bottom-up algorithm that computes \(\ENDLIS(i)\) for each \(i=0,1,\ldots,N\). Once we have these values, the actual (uncontrained) LIS length for \(S\) is simply the maximum value of \(\ENDLIS(i)\), taken over all \(i\). (This is because an LIS of \(S\) must end with some \(S[i]\) value, so its length is given by \(\ENDLIS(i)\).) As with weighted task selection, we can also store “backpointers” while filling in the \(\ENDLIS\) table, and backtrack through the table to find the actual elements of a longest increasing subsequence.
How efficient is this algorithm? We must compute the \(N\) (non-base-case) values of \(\ENDLIS(i)\) (for \(i=1,\ldots,N\)), and for each value we scan over all the elements of \(S[0,\ldots,i-1]\) (to compare them with \(S[i]\)), as well as all the previous values of \(\ENDLIS\) in the worst case. Thus, it takes \(\O(N)\) time to compute \(\ENDLIS(i)\) for a single \(i\), and hence \(\O(N^2)\) time to compute them all. Then, finding the maximum \(\ENDLIS(i)\) value takes \(\O(n)\) time, as does the backtracking. So the algorithm as a whole takes \(\O(N^2)\) time, and it uses \(\O(N)\) space.
Longest Common Subsequence
As a richer example of dynamic programming, consider the problem of finding a longest common subsequence of two given strings. A subsequence of a string is a selection of zero or more of its characters, preserving their original order. (Alternatively, a subsequence is obtained by deleting zero or more of the string’s characters.) The characters of the subsequence need not be adjacent in the original string. [8] For example, the following are subsequences of the string \(\texttt{Fibonacci sequence}\):
\(\texttt{Fun}\)
\(\texttt{seen}\)
\(\texttt{cse}\)
A common subsequence (CS) of two strings is a string that can be obtained as a subsequence of both strings, and a longest common subsequence (LCS) is one of maximum length. For instance, for the two strings \(\texttt{Go blue!}\) and \(\texttt{Wolverines}\), some common subsequences are \(\texttt{l}\), \(\texttt{le}\), and \(\texttt{ole}\). There is no common subsequence of length 4 or more, so \(\texttt{ole}\) is an LCS. As in the other problems considered above, in general an LCS is not unique (there can be multiple common subsequences of maximum length), though in this specific example it is unique.
Finding a longest common subsequence is useful in many applications, including DNA sequencing and computing the similarity between two texts. So, we wish to devise an efficient algorithm for determining an LCS of two input strings.
As we did above, let’s temporarily set aside the problem of finding an LCS string itself, and first focus on just computing its length. For any two strings \(S_1,S_2\), define \(\LCS(S_1,S_2)\) to be the length of any LCS of the strings. To get a dynamic-programming algorithm, we first need to discover a recurrence relation and base case(s) that relate the LCS length for \(S_1\) and \(S_2\) to the LCS lengths for appropriate smaller subinputs.
Let \(N,M\) respectively be the lengths of \(S_1,S_2\). First, we give the trivial base cases: if either string is the empty string—i.e., if \(N=0\) or \(M=0\) (or both)—then clearly \(\LCS(S_1,S_2) = 0\), because the only common subsequence is the empty sequence.
Now suppose that both \(N,M \geq 1\), and consider just the last character in each of the strings. [9] There are two possibilities: either these characters are the same, or they are different. We first consider the consequences of the former case, which is depicted in the following figure.

If \(S_1[N]=S_2[M]\), then there exists some LCS \(C\) of \(S_1\) and \(S_2\) that is obtained by selecting both \(S_1[N]\) and \(S_2[M]\) (and therefore ends with that character).
We emphasize that Lemma 31 says not only that \(C\) ends with the character that appears at the end of both strings, but also that it specifically selects both \(S_1[N]\) and \(S_2[M]\). For example, if \(S_1=\texttt{xyx}\) and \(S_2=\texttt{x}\), then \(\texttt{x}\) is an LCS, but selecting the first \(\texttt{x}\) from \(S_1\) would not satisfy the claim, while taking the final \(\texttt{x}\) from \(S_1\) would. (The distinction is important for what we will show below.)
Let \(x\) denote the character \(S_1[N]=S_2[M]\). First consider any common subsequence \(C'\) of \(S_1\) and \(S_2\) that selects neither \(S_1[N]\) nor \(S_2[M]\). Then we can get a common subsequence that is even longer than \(C'\) by also selecting \(S_1[N]=S_2[M]\) and appending it to \(C'\), so \(C'\) is not an LCS. Therefore, any LCS must select at least one of \(S_1[N]\) or \(S_2[M]\).
Now let \(C^*\) be an arbitrary LCS of \(S_1\) of \(S_2\). If \(C^*\) happens to select both \(S_1[N]\) and \(S_2[M]\), then the claim holds with \(C=C^*\), and we are done. So, suppose that \(C^*\) selects just one of those two characters, say \(S_1[N]\) without loss of generality (the other case proceeds symmetrically). Since \(C^*\) ends with \(x=S_1[N]\), the final selected character of \(S_2\) is also \(x\), which appears somewhere before \(S_2[M]\). So, we can modify the selected characters of \(S_2\) to “unselect” that final \(x\) and select \(S_2[M]=x\) instead. This results in the same common subsequence string \(C=C^*\), but it is obtained by selecting both \(S_1[N]\) and \(S_2[M]\), and it is an LCS of \(S_1,S_2\) because \(C^*\) is an LCS of \(S_1,S_2\) by hypothesis. This proves the claim.
We now get the following consequence of Lemma 31. It says that when \(S_1[N]=S_2[M]\), an LCS of \(S_1\) and \(S_2\) can be obtained by taking any LCS of the prefix strings \(S_1[1,\ldots,N-1]\) and \(S_2[1,\ldots,M-1]\), then appending the final shared character.
If \(S_1[N]=S_2[M]\), the common subsequences of \(S_1\) and \(S_2\) that select both \(S_1[N],S_2[M]\) are exactly the common subsequences of \(S_1[1,\ldots,N-1]\) and \(S_2[1,\ldots,M-1]\), with \(S_1[N]=S_2[M]\) also selected and appended. It follows that
In one direction, we can take any common subsequence of the prefix strings \(S_1[1,\ldots,N-1], S_2[1,\ldots,M-1]\), then append \(S_1[N]=S_2[M]\), to get a common subsequence of \(S_1,S_2\) that selects both \(S_1[N],S_2[M]\). In the other direction, let \(C\) be any common subsequence of \(S_1,S_2\) that selects both \(S_1[N],S_2[M]\); these selections must correspond to the final character of \(C\). So, removing the final character of \(C\) corresponds to “unselecting” \(S_1[N]\) and \(S_2[M]\), which yields a common subsequence of the prefix strings. This proves the first claim.
For the second claim, the above correspondence implies that any longest common subsequence of \(S_1,S_2\) that selects both \(S_1[N],S_2[M]\) is in fact a longest common subsequence of the prefix strings, plus one character. Moreover, Lemma 31 says that the “selects both \(S_1[N],S_2[M]\)” restriction does not affect the optimal length, because there exists an LCS of \(S_1,S_2\) that meets this requirement. So, the LCS length for \(S_1,S_2\) (without any requirement on what characters are selected) is indeed one larger than the LCS length for the prefix strings, as claimed.
Now we consider the case where the final characters of the two strings are different. The following lemma says that the LCS length is the maximum of the two LCS lengths where one of the strings remains unmodified, and the other is truncated by removing its final character. See the depiction in the following figure.


If \(S_1[N] \neq S_2[M]\), then
In any common subsequence of \(S_1,S_2\), the final character of at least one of the strings is not selected (because the final characters would have to appear at the end of the subsequence, and they do not match). Note that this could apply to either, or both, of the strings.
Next, observe that any common subsequence of \(S_1,S_2\) that does not select \(S_1[N]\) is also a common subsequence of \(S_1[1,\ldots,N-1]\) and \(S_2\), and vice versa. In other words, these two collections of subsequences are identical, and hence have the same maximum length.
Symmetrically, the same correspondence holds between the common subsequences of \(S_1,S_2\) that do not select \(S_2[M]\), and the common subsequences of \(S_1\) and \(S_2[1,\ldots,M-1]\).
Since any common subsequence of \(S_1,S_2\) does not select \(S_1[N]\) or \(S_2[M]\) (or both), the length of a longest common subsequence of \(S_1,S_2\) is the maximum of the longest in each of the above two cases, as claimed.
Putting all of the above together, we have arrived at our final overall recurrence for the LCS length:
For \(S_1=S_1[1,\ldots,N]\) and \(S_2=S_2[1,\ldots,M]\),
Now that we have a complete recurrence relation, we can proceed to give an algorithm, using the bottom-up approach.
We first observe that the recurrence refers only to subinputs consisting of a prefix \(S_1\) and a prefix of \(S_2\). So, our algorithm will compute and store the value of the \(\LCS\) function for every pair of such prefixes. That is, it will fill an \((N+1)\)-by-\((M+1)\) table in which the \((i,j)\)th entry is \(\LCS(S_1[1,\ldots,i], S_2[1,\ldots,j])\), for all \(i \in [0,N]\) and \(j \in [0,M]\). (By convention, \(S_1[1,\ldots,0]\) denotes the empty string, and similarly for \(S_2[1,\ldots,0]\).).
For example, below is the complete table for the strings \(S_1 = \texttt{Go blue!}\) and \(S_2 = \texttt{Wolverines}\), which has been filled using the recurrence from Theorem 37.

As mentioned above, the \((i,j)\)th entry of the table holds the LCS length for \(S_1[1,\ldots,i]\) and \(S_2[1,\ldots,j]\). Using the recurrence relation, we can compute the value of the \((i,j)\)th entry from the entries at the three locations \((i-1,j-1)\), \((i-1,j)\), and \((i,j-1)\); the first one is used when \(S_1[i] = S_2[j]\), and the latter two are used when \(S_1[i] \ne S_2[j]\). Entry \((N,M)\) holds the LCS length for the full strings \(S_1[1,\ldots,N]\) and \(S_2[1,\ldots,M]\).
The last thing we need before writing the algorithm is to determine a valid order in which to compute and fill the table entries. The only requirement is that before computing entry \((i,j)\) for \(i,j>0\), the entries \((i-1,j-1), (i-1,j), (i,j-1)\) should already have been computed and filled in. There are multiple orders that meet this requirement; we will compute the entries row by row from top to bottom (i.e., with increasing \(i\)), moving left to right within each row (i.e., with increasing \(j\)).
We now give the pseudocode for computing all the entries of the table.
Now that we have shown how to compute the length of a longest common subsequence, let’s return to the original problem of computing such a subsequence itself. As in our previous examples, we can backtrack through the table to recover the characters of an LCS, from back to front. We start with the bottom-right entry \((N,M)\), and backtrack through a path until we reach some base-case entry. For each (non-base-case) entry \((i,j)\) on the path, we check to see if the characters corresponding to that entry match, i.e., if \(S_1[i]=S_2[j]\). If so, we prepend the matching character to our partial LCS, and we backtrack to entry \((i-1,j-1)\). If the characters do not match, we look at the entries above and to the left—namely, \((i-1,j)\) and \((i,j-1)\)—and backtrack to whichever one is larger (breaking a tie arbitrarily). This is because the larger of the two entries corresponds to the \(\max\) value in the recurrence, i.e., it yields a longer completion of our partial LCS.
The following demonstrates a valid backtracking path for our example strings and LCS table. The solid path uses some arbitrary choices to break ties, while the dashed path always goes left in case of a tie. Both paths result in a valid LCS (and in this case, the same set of characters, though that isn’t necessarily the case for all pairs of strings).

The algorithm for backtracking is as follows:
How efficient is this algorithm? Computing a single table entry requires a constant number of operations, because it simply compares two characters of the strings, looks at one or two neighboring entries, and either adds 1 or takes a maximum. Since there are \((N+1) \cdot (M+1)\) entries overall, constructing the table takes \(\O(NM)\) time and requires \(\O(NM)\) space. Backtracking also does a constant number of operations per entry on the path, and the path takes at most \(N+M\) steps, so backtracking takes \(\O(N+M)\) time. Thus, this algorithm uses a total of \(\O(NM)\) time and space.
All-Pairs Shortest Paths
Suppose you are building a flight-aggregator website. Each day, you receive a list of flights from several airlines with their associated costs, and some flight segments may actually have negative cost if the airline wants to incentivize a particular route (see hidden-city ticketing for an example of how this can be exploited in practice, and what the perils of doing so are). You’d like your users to be able to find the cheapest itinerary from point A to point B. To provide this service efficiently, you determine in advance the cheapest itineraries between all possible origin and destination locations, so that you need only look up an already computed result when the user puts in a query.
This situation is an example of the all-pairs shortest path problem. The set of cities and flights can be represented as a graph \(G = (V,E)\), with the cities represented as vertices and the flight segments as edges in the graph. There is also a weight function \(weight: E\to\R\) that maps each edge to a cost. While an individual edge may have a negative cost, no negative cycles are allowed. (Otherwise a traveler could just fly around that cycle to make as much money as they want, which would be very bad for the airlines!) Our task is to find the lowest-cost path between all pairs of vertices in the graph.
How can we apply dynamic programming to this problem? We need to formulate it such that there are self-similar subproblems. To gain some insight, we observe that many aggregators allow the selection of layover airports, which are intermediate stops between the origin and destination, when searching for flights. The following is an example from kayak.com.

We take the set of allowed layover airports as one of the key characteristics of a subproblem – computing shortest paths with a smaller set of allowed layover airports is a subproblem of computing shortest paths with a larger set of allowed layover airports. Then the base case is allowing only direct flights, with no layover airports.
Coming back to the graph representation of this problem, we formalize the notion of a layover airport as an intermediate vertex of a simple path, which is a path without cycles. Let \(p = \{v_1, v_2, \dots, v_m\}\) be a path from origin \(v_1\) to destination \(v_m\). Then \(v_2, \dots, v_{m-1}\) are intermediate vertices.
Assume that the vertices are labeled as numbers in the set \(\{1, 2, \dots, \abs{V}\}\). We parameterize a subproblem by \(k\), which signifies that the allowed set of intermediate vertices (layover airports) is restricted to \(\{1, 2, \dots, k\}\). Then we define \(d^k(i,j)\) to be the length of the shortest path between vertices \(i\) and \(j\), where the path is only allowed to go through intermediate vertices in the set \(\{1, 2, \dots, k\}\).
We have already determined that when no intermediate vertices are allowed, which is when \(k = 0\), the shortest path between \(i\) and \(j\) is just the direct edge (flight) between them. Thus, our base case is
where \(\weight(i,j)\) is the weight of the edge between \(i\) and \(j\).
We proceed to the recursive case. We have at our disposal the value of \(d^{k-1}(i',j')\) for all \(i',j' \in V\), and we want to somehow relate \(d^k(i,j)\) to those values. The latter represents adding vertex \(k\) to our set of permitted intermediate vertices. There are two possible cases for the shortest path between \(i\) and \(j\) that is allowed to use any of the intermediate vertices \(1, 2, \dots, k\):
Case 1: The path does not go through \(k\). Then the length of the shortest path that is allowed to go through \(1, 2, \dots, k\) is the same as that of the shortest path that is only allowed to go through \(1, 2, \dots, k-1\), so \(d^k(i,j) = d^{k-1}(i,j)\).
Case 2: The path does go through \(k\). Then this path is composed of two segments, one that goes from \(i\) to \(k\) and another that goes from \(k\) to \(j\). We minimize the cost of the total path by minimizing the cost of each of the segments – the costs respect the principle of optimality.
Neither of the two segments may have \(k\) as an intermediate vertex – otherwise we would have a cycle. The only way for a path with a cycle to have lower cost than one without is for the cycle as a whole to have negative weight, which was explicitly prohibited in our problem statement. Since \(k\) is not an intermediate vertex in the segment between \(i\) and \(k\), the shortest path between them that is allowed to go through intermediate vertices \(1, 2, \dots, k\) is the same as the shortest path that is only permitted to go through \(1, 2, \dots, k-1\). In other words, the length of this segment is \(d^{k-1}(i,k)\). By the same reasoning, the length of the segment between \(k\) and \(j\) is \(d^{k-1}(k,j)\).
Thus, we have that in this case, \(d^k(i,j) = d^{k-1}(i,k) + d^{k-1}(k,j)\).
We don’t know a priori which of these two cases holds, but we can just compute them both and take the minimum. This gives us the recursive case:
Combining this with the base case, we have our complete recurrence relation:
We can now construct a bottom-up algorithm to compute the shortest paths:
This is known as the Floyd-Warshall algorithm, and it runs in time \(\O(\abs{V}^3)\). The space usage is \(\O(\abs{V}^2)\) if we only keep around the computed values of \(d^m(i,j)\) for iterations \(m\) and \(m+1\). Once we have computed these shortest paths, we need only look up the already computed result to find the shortest path between a particular origin and destination.
Greedy Algorithms
A greedy algorithm computes a solution to an optimization problem by making (and committing to) a sequence of locally optimal choices. In general, there is no guarantee that such a sequence of locally optimal choices produces a global optimum. However, for some specific problems and greedy algorithms, we can prove that the result is indeed a global optimum.
As an example, consider the problem of finding a minimum spanning tree (MST) of a weighted, connected, undirected graph. Given such a graph, we would like to find a subset of the edges so that the subgraph induced by those edges touches every vertex, is connected, and has minimum total edge cost. This is an important problem in designing networks, including transportation and communication networks, where we want to ensure that there is a path between any two vertices while minimizing the overall cost of the network.
Before we proceed, let’s review the definition of a tree. There are three equivalent definitions:
An undirected graph \(G\) is a tree if it is connected and acyclic (i.e., has no cycle).
A graph is connected if for any two vertices there is a path between them. A cycle is a nonempty sequence of adjacent edges that starts and ends at the same vertex.
An undirected graph \(G\) is a tree if it is minimally connected, i.e., if it is connected, and removing any single edge causes it to become disconnected.
An undirected graph \(G\) is a tree if it is maximally acyclic, i.e., if it has no cycle, and adding any single edge causes it to have a cycle.
Show that the three definitions of a tree are equivalent.
A minimum spanning tree (MST) of a connected graph is a subset of its edges that:
connects all the vertices,
is acyclic,
and has minimum total edge weight over all subsets that meet the first two requirements.
The first two requirements imply that an MST (together with all the graph’s vertices) is indeed a tree, by Definition 41. Since the tree spans all the vertices of the graph, we call it a spanning tree. A minimum spanning tree is then a spanning tree that has the minimum weight over all spanning trees of the original graph.
The following illustrates three spanning trees of an example graph. The middle one is an MST, since its total weight of 8 is no larger than that of any other spanning tree.

A graph may have multiple minimum spanning trees (so we say “an MST,” not “the MST,” unless we have some specific MST in mind, or have a guarantee that there is a unique MST in the graph). In the following graph, any two edges form an MST.

Now that we understand what a minimum spanning tree is, let’s consider Kruskal’s algorithm, a greedy algorithm for computing an MST in a given graph. The algorithm simply examines the edges in sorted order by weight (from smallest to largest), selecting any edge that does not induce a cycle when added to the set of already-selected edges. It is “greedy” because it repeatedly selects an edge of minimum weight that does not induce a cycle (a locally optimal choice), and once it selects an edge, it never “un-selects” it (each choice is committed).
As an example, let’s see how Kruskal’s algorithm computes an MST of the following graph. We start by sorting the edges by their weights.

Then we consider the edges in order, including each edge in our partial result as long as adding it does not introduce a cycle among our selected edges.
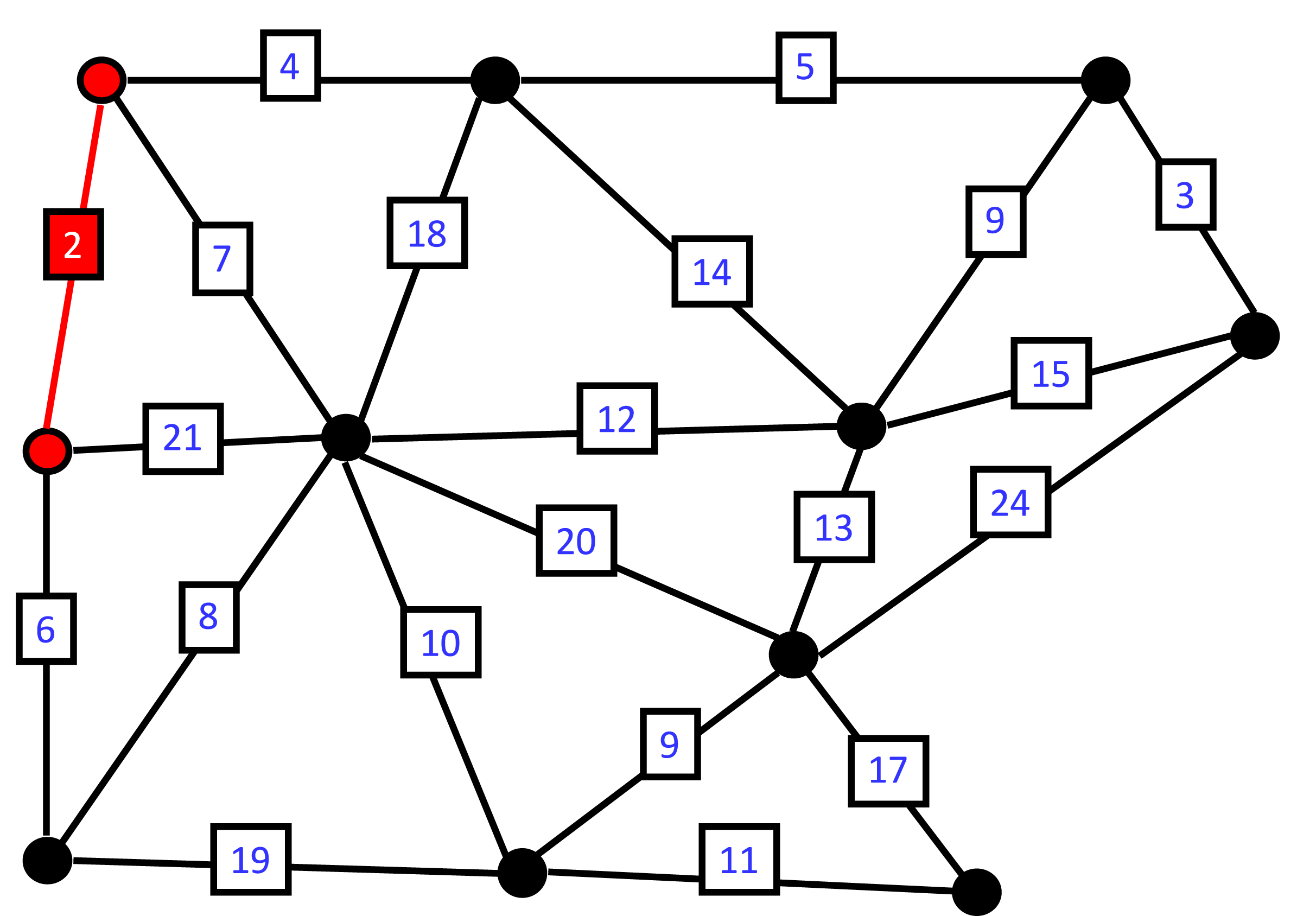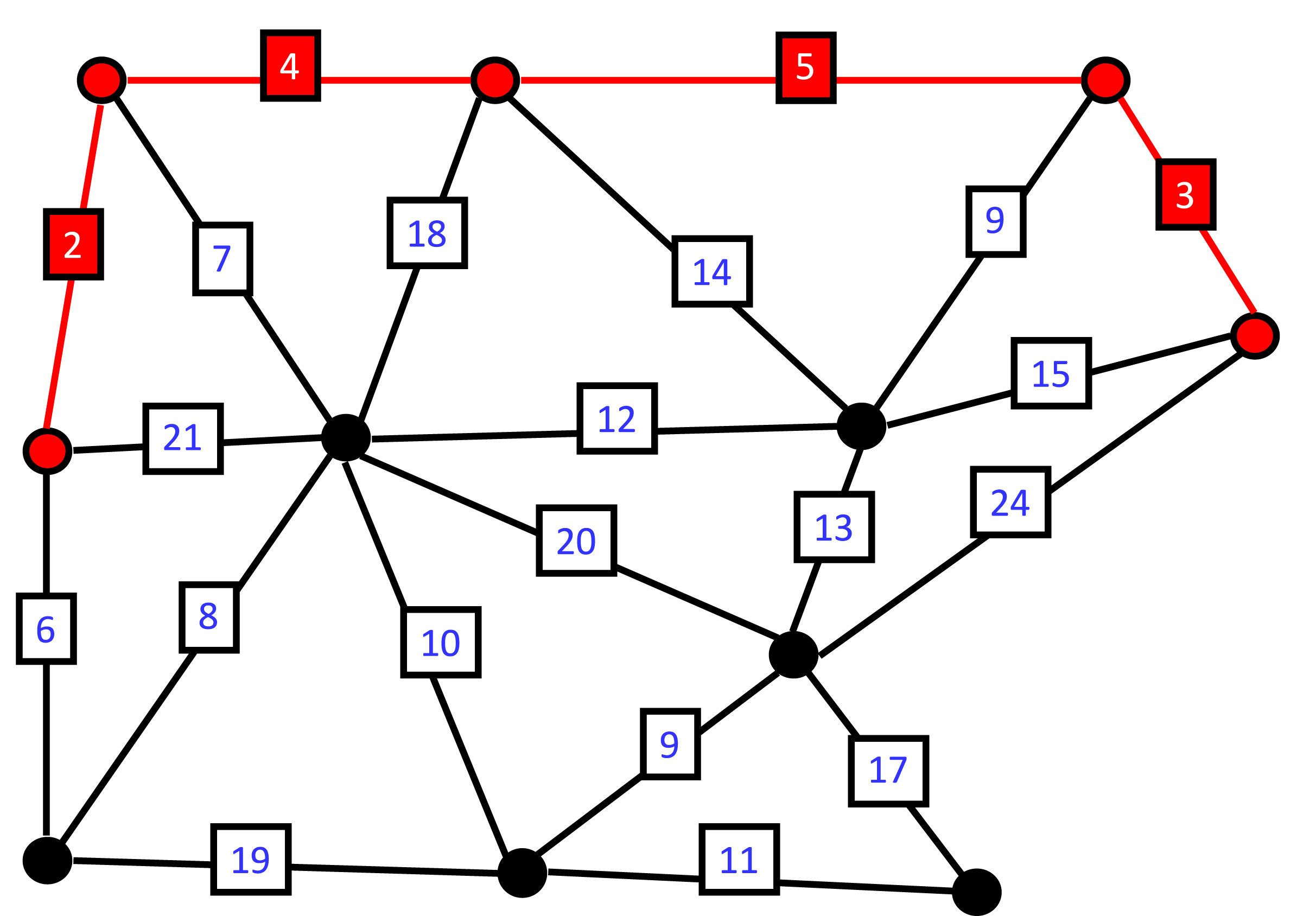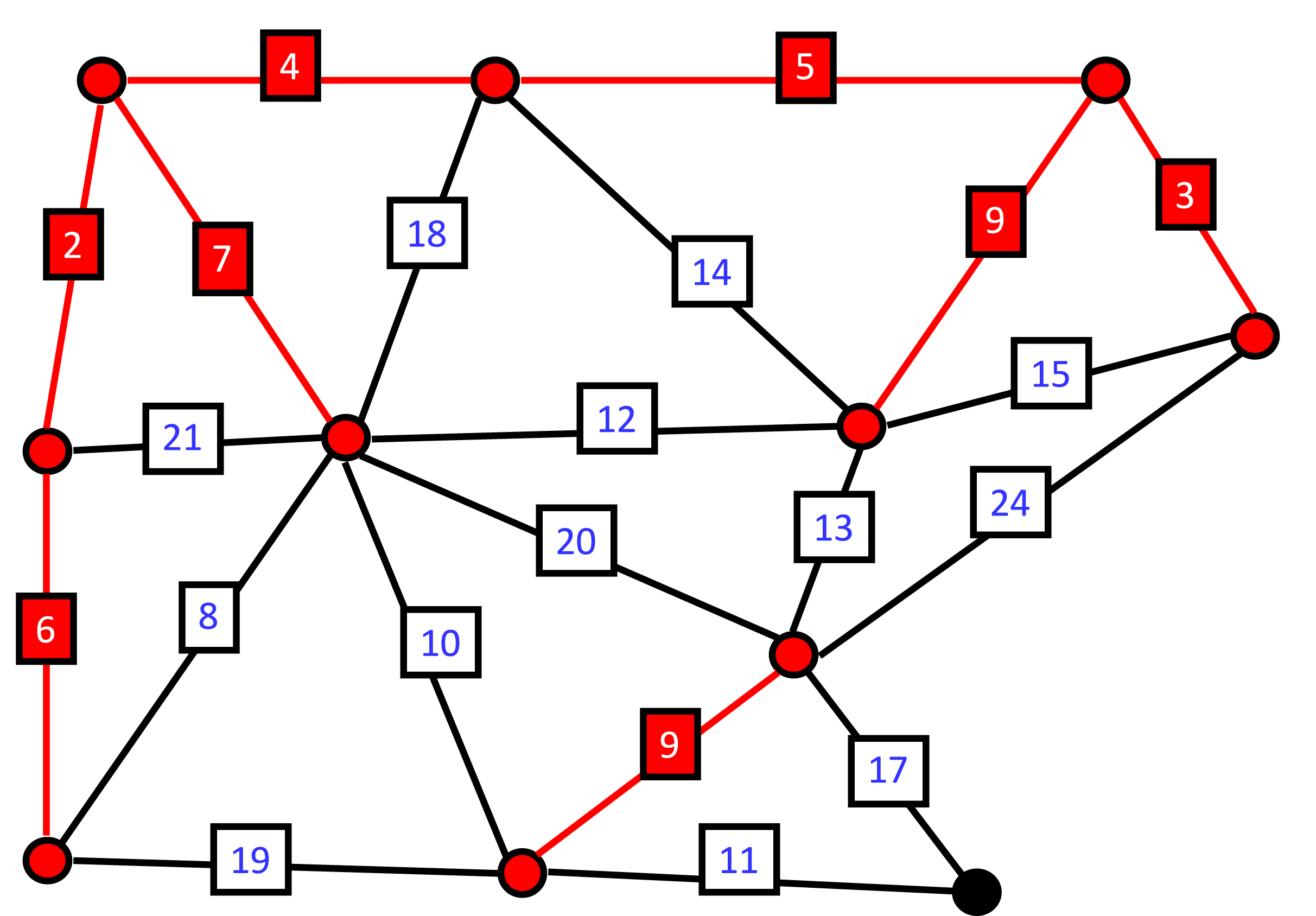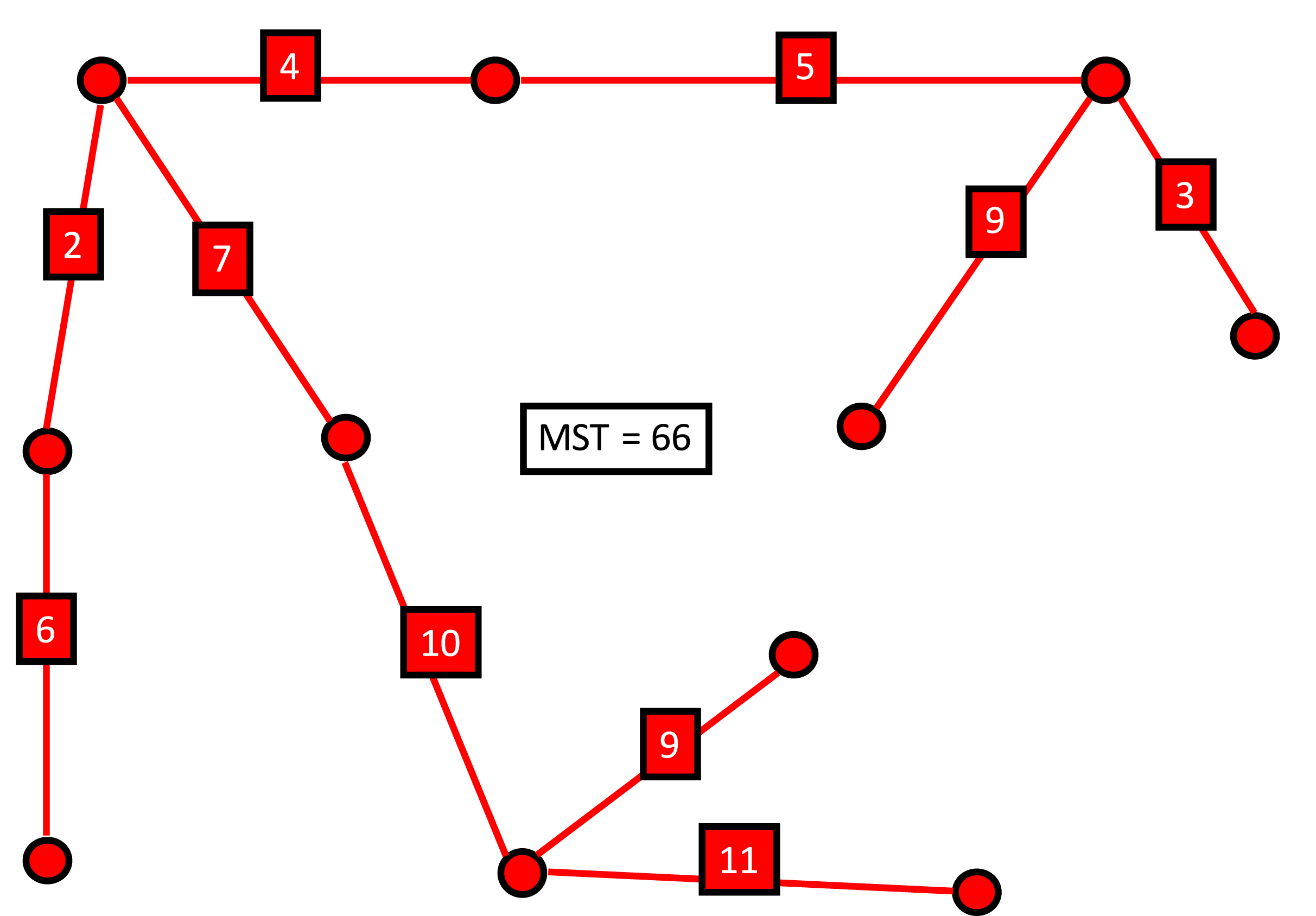
Observe that when the algorithm considers the edge with weight 8, the two incident vertices are already connected by the already-selected edges, so adding that edge would introduce a cycle. Thus, the algorithm skips it and continues on to the next edge. In this graph, there are two edges of weight 9, so the algorithm arbitrarily picks one of them to consider first. The algorithm terminates when all edges have been examined. For this graph, the resulting spanning tree has a total weight of 66.
As stated previously, for many problems it is not the case that a sequence of locally optimal choices yields a global optimum. But as we will now show, for the MST problem, it turns out that Kruskal’s algorithm does indeed produce a minimum spanning tree.
The output of Kruskal’s algorithm is a tree.
To prove this, we will assume for convenience that the input graph \(G\) is complete, meaning that there is an edge between every pair of vertices. We can make any graph complete by adding the missing edges with infinite weight, so that the new edges do not change the minimum spanning trees.
Let \(T\) be the output of Kruskal’s algorithm, which is the final value of \(S\), on a complete input graph \(G\). Recall from Definition 43 that a tree is a maximally acyclic graph. Clearly \(T\) is acyclic, since Kruskal’s algorithm initializes \(S\) to be the empty set, which is acylic, and it adds an edge to \(S\) only if it does not induce a cycle.
So, it just remains to show that \(T\) is maximal. By definition, we need to show that for any potential edge \(e \notin T\) between two vertices of \(T\), adding \(e\) to \(T\) would introduce a cycle. The input graph is complete, and the algorithm examined each of its edges, so it must have considered \(e\) at some point. Because \(T\) does not contain \(e\), and no edge was ever removed from \(S\), the algorithm did not add \(e\) to \(S\) when it considered \(e\). Recall that when the algorithm considers an edge, it leaves it out of \(S\) only if it would create a cycle in \(S\) (at that time). So, since it did not add \(e\) to \(S\), doing so would have induced a cycle at the time. And since no edges are ever removed from \(S\), adding \(e\) to the final output \(T\) also would induce a cycle, which is what we set out to show. Thus, \(T\) is maximal, as desired.
We can similarly demonstrate that the output of Kruskal’s algorithm is a spanning tree, but we leave that as an exercise.
Show that if the input graph \(G\) is connected, then the output of Kruskal’s algorithm spans all the vertices of \(G\).
Next, we show that the result of Kruskal’s algorithm is a minimum spanning tree. To do so, we actually prove a stronger claim:
At any point in Kruskal’s algorithm on an input graph \(G\), let \(S\) be the set of edges that have been selected so far. Then there is some minimum spanning tree of \(G\) that contains \(S\).
Since this claim holds at any point in Kruskal’s algorithm, in particular it holds for the final output set of edges \(T\), i.e., there is an MST that contains \(T\). Since we have already seen above that \(T\) is a spanning tree, no edge of the graph can be added to \(T\) without introducing a cycle, so we can conclude that the MST containing \(T\) as guaranteed by Claim 50 must be \(T\) itself, and hence \(T\) is an MST.
We prove Claim 50 by induction over the size of \(S\), i.e., the sequence of edges added to it by the algorithm.
Base case: \(S = \emptyset\) is the empty set. Every MST trivially contains \(\emptyset\) as a subset, so the claim holds.
Inductive step: Let \(T\) be an MST that contains \(S\). Suppose the algorithm would next add edge \(e\) to \(S\). We need to show that there is some MST \(T'\) that contains \(S \cup \set{e}\).
There are two possibilities: either \(e \in T\), or not.
Case 1: \(e \in T\). The claim follows immediately: since \(T\) is an MST that contains \(S\), and also \(e \in T\), then \(T\) is an MST that contains \(S \cup \set{e}\). (In other words, we can take \(T' = T\) in this case.)
Case 2: \(e \notin T\). Then by Definition 43, \(T \cup \set{e}\) contains some cycle \(C\), and \(e \in C\) because \(T\) alone is acyclic.
By the code of Kruskal’s algorithm, we know that \(S \cup \set{e}\) does not contain a cycle. Thus, there must be some edge \(f \in C\) for which \(f \notin S \cup \set{e}\), and in particular, \(f \neq e\). Since \(f \in C \subseteq T \cup \set{e}\), we have that \(f \in T\).
Observe that \(S \cup \set{f} \subseteq T\), since \(S \subseteq T\) by the inductive hypothesis. Since \(T\) does not contain a cycle, neither does \(S \cup \set{f}\).
Since adding \(f\) to \(S\) would not induce a cycle, the algorithm must not have considered \(f\) yet (at the time it considers \(e\) and adds it to \(S\)), or else it would have added \(f\) to \(S\). Because the algorithm considers edges in sorted order by weight, and it has considered \(e\) but has not considered \(f\) yet, it must be that \(w(e) \leq w(f)\).
Now define \(T' = T \cup \set{e} \setminus \set{f}\), which has weight \(w(T') = w(T) + w(e) - w(f) \leq w(T)\). Moreover, \(T'\) is a spanning tree of \(G\): for any two vertices, there is a path between them that follows such a path in \(T\), but instead of using edge \(f\) it instead goes the “other way around” the cycle \(C\) using the edges of \(C \setminus \set{f} \subseteq T'\).
Since \(T'\) is a spanning tree whose weight is no larger than that of \(T\), and \(T\) is an MST, \(T'\) is also an MST. [10] And since \(S \subseteq T\) and \(f \notin S\), we have that \(S \cup \set{e} \subseteq T \cup \set{e} \setminus \set{f} = T'\). Thus, \(T'\) is an MST that contains \(S \cup \set{e}\), as needed.
We have proved that Kruskal’s algorithm does indeed output an MST of its input graph. We also state without proof that its running time on an input graph \(G = (E,V)\) is \(\O(\abs{E} \log \abs{E})\), by using an appropriate choice of supporting data structure to detect for cycles.
Observe that the analysis of Kruskal’s algorithm is nontrivial. This is often the case for greedy algorithms. Again, it is usually not the case that locally optimal choices lead to a global optimum, so we typically need to do significant work to demonstrate that this is actually the case for a particular problem and algorithm.
A standard strategy for proving that a greedy algorithm correctly solves a particular optimization problem proceeds by establishing a “greedy choice” property, often by means of an exchange-style argument like the one we gave above for MSTs. A “greedy choice” property consists of two parts:
Base case: the algorithm’s initial state is contained in some optimal solution. Since a typical greedy algorithm’s initial state is the empty set, this property is usually easy to show.
Inductive step: for any (greedy) choice the algorithm makes, there remains an optimal solution that contains the algorithm’s set of choices so far. (Observe that Claim 50 has this form.)
With a greedy-choice property established, by induction, the algorithm’s set of choices is at all times contained in some optimal solution. So, it just remains to show that the final output consists of a full solution (not just a partial one); it therefore must be an optimal solution.
To show the inductive step of the greedy-choice property, we have the inductive hypothesis that the previous choices \(S\) are contained in some optimal solution \(\OPT\), and we need to show that the updated choices \(S \cup \set{s}\) are contained in some optimal solution \(\OPT'\). If \(s \in \OPT\), then the claim holds trivially. But if \(s \notin \OPT\), then we aim to invoke some exchange argument, which modifies \(\OPT\) to some other optimal solution \(\OPT'\) that contains \(S \cup \set{s}\). Indeed, this is exactly what we did in the correctness proof for Kruskal’s argument, by changing \(\OPT = T\) to \(\OPT' = T' = T \cup \set{e} \setminus \set{f}\), for some carefully identified edge \(f \in T\) whose weight is no smaller than that of \(e\). This means that \(\OPT'\) is also an optimal solution, as needed.